Note
Click here to download the full example code
Benchmark Random Forests, Tree Ensemble, (AoS and SoA)#
The script compares different implementations for the operator TreeEnsembleRegressor.
baseline: RandomForestRegressor from scikit-learn
ort: onnxruntime,
mlprodict: an implementation based on an array of structures, every structure describes a node,
mlprodict2 similar implementation but instead of having an array of structures, it relies on a structure of arrays, it parallelizes by blocks of 128 observations and inside every block, goes through trees then through observations (double loop),
mlprodict3: parallelizes by trees, this implementation is faster when the depth is higher than 10.
A structure of arrays has better performance: Case study: Comparing Arrays of Structures and Structures of Arrays Data Layouts for a Compute-Intensive Loop. See also AoS and SoA.
Profile the execution
py-spy can be used to profile the execution of a program. The profile is more informative if the code is compiled with debug information.
py-spy record --native -r 10 -o plot_random_forest_reg.svg -- python plot_random_forest_reg.py
Import#
import warnings
from time import perf_counter as time
from multiprocessing import cpu_count
import numpy
from numpy.random import rand
from numpy.testing import assert_almost_equal
import pandas
import matplotlib.pyplot as plt
from sklearn import config_context
from sklearn.ensemble import RandomForestRegressor
from sklearn.utils._testing import ignore_warnings
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
from onnxruntime import InferenceSession
from mlprodict.onnxrt import OnnxInference
Available optimisation on this machine.
from mlprodict.testing.experimental_c_impl.experimental_c import code_optimisation
print(code_optimisation())
Out:
AVX-omp=8
Versions#
def version():
from datetime import datetime
import sklearn
import numpy
import onnx
import onnxruntime
import skl2onnx
import mlprodict
df = pandas.DataFrame([
{"name": "date", "version": str(datetime.now())},
{"name": "numpy", "version": numpy.__version__},
{"name": "scikit-learn", "version": sklearn.__version__},
{"name": "onnx", "version": onnx.__version__},
{"name": "onnxruntime", "version": onnxruntime.__version__},
{"name": "skl2onnx", "version": skl2onnx.__version__},
{"name": "mlprodict", "version": mlprodict.__version__},
])
return df
version()
Implementations to benchmark#
def fcts_model(X, y, max_depth, n_estimators, n_jobs):
"RandomForestClassifier."
rf = RandomForestRegressor(max_depth=max_depth, n_estimators=n_estimators,
n_jobs=n_jobs)
rf.fit(X, y)
initial_types = [('X', FloatTensorType([None, X.shape[1]]))]
onx = convert_sklearn(rf, initial_types=initial_types)
sess = InferenceSession(onx.SerializeToString())
outputs = [o.name for o in sess.get_outputs()]
oinf = OnnxInference(onx, runtime="python")
oinf.sequence_[0].ops_._init(numpy.float32, 1)
name = outputs[0]
oinf2 = OnnxInference(onx, runtime="python")
oinf2.sequence_[0].ops_._init(numpy.float32, 2)
oinf3 = OnnxInference(onx, runtime="python")
oinf3.sequence_[0].ops_._init(numpy.float32, 3)
def predict_skl_predict(X, model=rf):
return rf.predict(X)
def predict_onnxrt_predict(X, sess=sess):
return sess.run(outputs[:1], {'X': X})[0]
def predict_onnx_inference(X, oinf=oinf):
return oinf.run({'X': X})[name]
def predict_onnx_inference2(X, oinf2=oinf2):
return oinf2.run({'X': X})[name]
def predict_onnx_inference3(X, oinf3=oinf3):
return oinf3.run({'X': X})[name]
return {'predict': (
predict_skl_predict, predict_onnxrt_predict,
predict_onnx_inference, predict_onnx_inference2,
predict_onnx_inference3)}
Benchmarks#
def allow_configuration(**kwargs):
return True
def bench(n_obs, n_features, max_depths, n_estimatorss, n_jobss,
methods, repeat=10, verbose=False):
res = []
for nfeat in n_features:
ntrain = 50000
X_train = numpy.empty((ntrain, nfeat)).astype(numpy.float32)
X_train[:, :] = rand(ntrain, nfeat)[:, :]
eps = rand(ntrain) - 0.5
y_train = X_train.sum(axis=1) + eps
for n_jobs in n_jobss:
for max_depth in max_depths:
for n_estimators in n_estimatorss:
fcts = fcts_model(X_train, y_train,
max_depth, n_estimators, n_jobs)
for n in n_obs:
for method in methods:
fct1, fct2, fct3, fct4, fct5 = fcts[method]
if not allow_configuration(
n=n, nfeat=nfeat, max_depth=max_depth,
n_estimator=n_estimators, n_jobs=n_jobs,
method=method):
continue
obs = dict(n_obs=n, nfeat=nfeat,
max_depth=max_depth,
n_estimators=n_estimators,
method=method,
n_jobs=n_jobs)
# creates different inputs to avoid caching
Xs = []
for r in range(repeat):
x = numpy.empty((n, nfeat))
x[:, :] = rand(n, nfeat)[:, :]
Xs.append(x.astype(numpy.float32))
# measures the baseline
with config_context(assume_finite=True):
st = time()
repeated = 0
for X in Xs:
p1 = fct1(X)
repeated += 1
if time() - st >= 1:
break # stops if longer than a second
end = time()
obs["time_skl"] = (end - st) / repeated
# measures the new implementation
st = time()
r2 = 0
for X in Xs:
p2 = fct2(X)
r2 += 1
if r2 >= repeated:
break
end = time()
obs["time_ort"] = (end - st) / r2
# measures the other new implementation
st = time()
r2 = 0
for X in Xs:
p2 = fct3(X)
r2 += 1
if r2 >= repeated:
break
end = time()
obs["time_mlprodict"] = (end - st) / r2
# measures the other new implementation 2
st = time()
r2 = 0
for X in Xs:
p2 = fct4(X)
r2 += 1
if r2 >= repeated:
break
end = time()
obs["time_mlprodict2"] = (end - st) / r2
# measures the other new implementation 3
st = time()
r2 = 0
for X in Xs:
p2 = fct5(X)
r2 += 1
if r2 >= repeated:
break
end = time()
obs["time_mlprodict3"] = (end - st) / r2
# final
res.append(obs)
if verbose and (len(res) % 1 == 0 or n >= 10000):
print("bench", len(res), ":", obs)
# checks that both produce the same outputs
if n <= 10000:
if len(p1.shape) == 1 and len(p2.shape) == 2:
p2 = p2.ravel()
try:
assert_almost_equal(
p1.ravel(), p2.ravel(), decimal=5)
except AssertionError as e:
warnings.warn(str(e))
return res
Graphs#
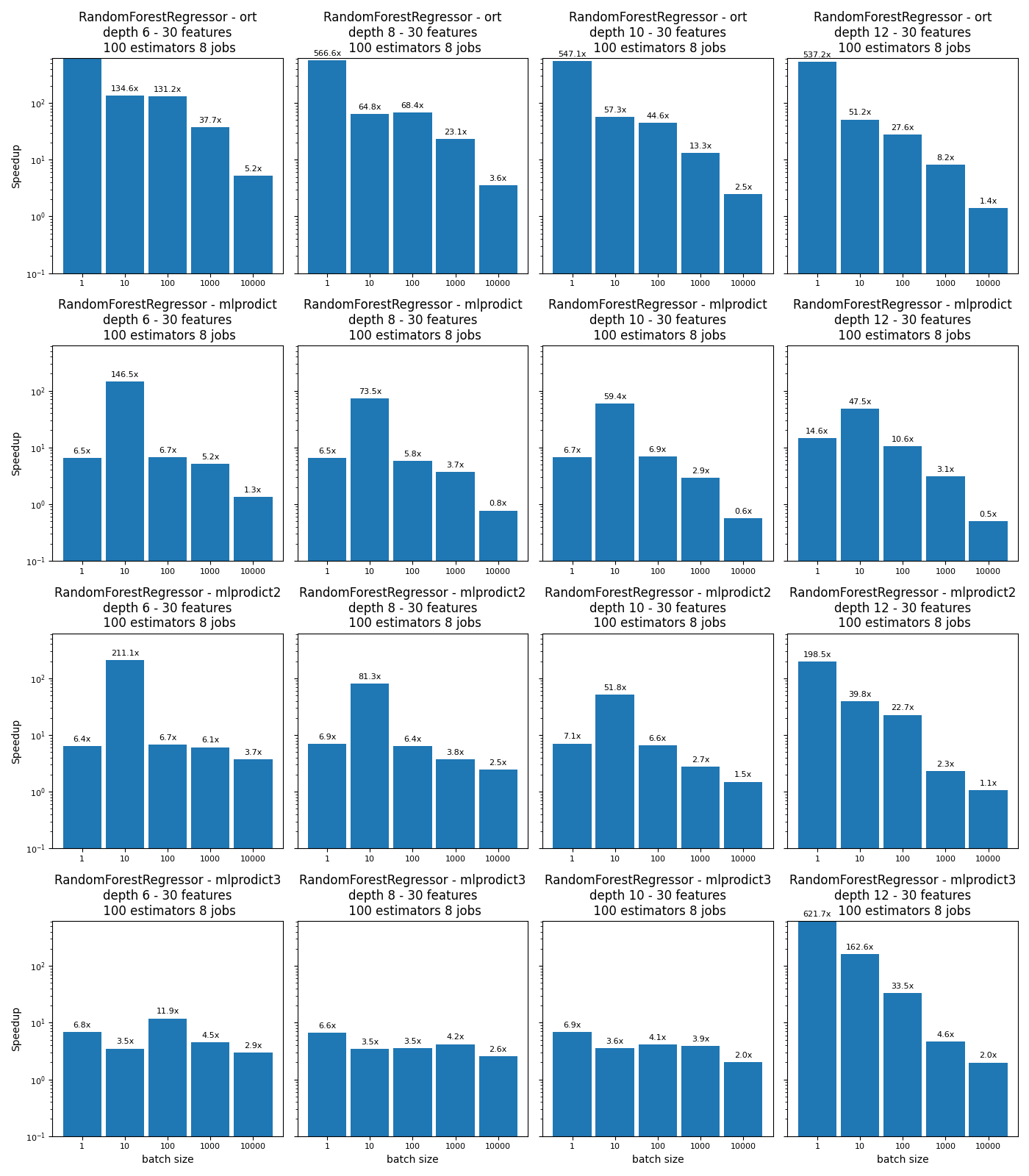
def plot_rf_models(dfr):
def autolabel(ax, rects):
for rect in rects:
height = rect.get_height()
ax.annotate('%1.1fx' % height,
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom',
fontsize=8)
engines = [_.split('_')[-1] for _ in dfr.columns if _.startswith("time_")]
engines = [_ for _ in engines if _ != 'skl']
for engine in engines:
dfr["speedup_%s" % engine] = dfr["time_skl"] / dfr["time_%s" % engine]
print(dfr.tail().T)
ncols = 4
fig, axs = plt.subplots(len(engines), ncols, figsize=(
14, 4 * len(engines)), sharey=True)
row = 0
for row, engine in enumerate(engines):
pos = 0
name = "RandomForestRegressor - %s" % engine
for max_depth in sorted(set(dfr.max_depth)):
for nf in sorted(set(dfr.nfeat)):
for est in sorted(set(dfr.n_estimators)):
for n_jobs in sorted(set(dfr.n_jobs)):
sub = dfr[(dfr.max_depth == max_depth) &
(dfr.nfeat == nf) &
(dfr.n_estimators == est) &
(dfr.n_jobs == n_jobs)]
ax = axs[row, pos]
labels = sub.n_obs
means = sub["speedup_%s" % engine]
x = numpy.arange(len(labels))
width = 0.90
rects1 = ax.bar(x, means, width, label='Speedup')
if pos == 0:
ax.set_yscale('log')
ax.set_ylim([0.1, max(dfr["speedup_%s" % engine])])
if pos == 0:
ax.set_ylabel('Speedup')
ax.set_title(
'%s\ndepth %d - %d features\n %d estimators %d '
'jobs' % (name, max_depth, nf, est, n_jobs))
if row == len(engines) - 1:
ax.set_xlabel('batch size')
ax.set_xticks(x)
ax.set_xticklabels(labels)
autolabel(ax, rects1)
for tick in ax.xaxis.get_major_ticks():
tick.label.set_fontsize(8)
for tick in ax.yaxis.get_major_ticks():
tick.label.set_fontsize(8)
pos += 1
fig.tight_layout()
return fig, ax
Run benchs#
@ignore_warnings(category=FutureWarning)
def run_bench(repeat=100, verbose=False):
n_obs = [1, 10, 100, 1000, 10000]
methods = ['predict']
n_features = [30]
max_depths = [6, 8, 10, 12]
n_estimatorss = [100]
n_jobss = [cpu_count()]
start = time()
results = bench(n_obs, n_features, max_depths, n_estimatorss, n_jobss,
methods, repeat=repeat, verbose=verbose)
end = time()
results_df = pandas.DataFrame(results)
print("Total time = %0.3f sec cpu=%d\n" % (end - start, cpu_count()))
# plot the results
return results_df
name = "plot_random_forest_reg"
df = run_bench(verbose=True)
df.to_csv("%s.csv" % name, index=False)
df.to_excel("%s.xlsx" % name, index=False)
fig, ax = plot_rf_models(df)
fig.savefig("%s.png" % name)
plt.show()
Out:
bench 1 : {'n_obs': 1, 'nfeat': 30, 'max_depth': 6, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.05573259542385737, 'time_ort': 8.528462300697963e-05, 'time_mlprodict': 0.008581353144513236, 'time_mlprodict2': 0.00873697487016519, 'time_mlprodict3': 0.008161399823923906}
bench 2 : {'n_obs': 10, 'nfeat': 30, 'max_depth': 6, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.055635006373955145, 'time_ort': 0.0004133107140660286, 'time_mlprodict': 0.0003797211166885164, 'time_mlprodict2': 0.0002635866403579712, 'time_mlprodict3': 0.015889178030192852}
bench 3 : {'n_obs': 100, 'nfeat': 30, 'max_depth': 6, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.059637165025753135, 'time_ort': 0.00045464889091603896, 'time_mlprodict': 0.008950498941190103, 'time_mlprodict2': 0.008859267567887026, 'time_mlprodict3': 0.005013359162737341}
bench 4 : {'n_obs': 1000, 'nfeat': 30, 'max_depth': 6, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.08179497647170837, 'time_ort': 0.0021723667876078533, 'time_mlprodict': 0.015863266988442495, 'time_mlprodict2': 0.013377069710538937, 'time_mlprodict3': 0.018311162407581624}
bench 5 : {'n_obs': 10000, 'nfeat': 30, 'max_depth': 6, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.10728115364909172, 'time_ort': 0.020656468719244002, 'time_mlprodict': 0.08076727837324142, 'time_mlprodict2': 0.02906704768538475, 'time_mlprodict3': 0.03656003475189209}
bench 6 : {'n_obs': 1, 'nfeat': 30, 'max_depth': 8, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.05526429855901944, 'time_ort': 9.753535452641939e-05, 'time_mlprodict': 0.008471277395361349, 'time_mlprodict2': 0.007965212589816043, 'time_mlprodict3': 0.008332478862844016}
bench 7 : {'n_obs': 10, 'nfeat': 30, 'max_depth': 8, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.05593731440603733, 'time_ort': 0.0008637115566266908, 'time_mlprodict': 0.0007608810232745276, 'time_mlprodict2': 0.0006883084360096189, 'time_mlprodict3': 0.016098013044231467}
bench 8 : {'n_obs': 100, 'nfeat': 30, 'max_depth': 8, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.06037295149529681, 'time_ort': 0.0008827326271463843, 'time_mlprodict': 0.010462815708973828, 'time_mlprodict2': 0.009450215408030678, 'time_mlprodict3': 0.017118924242608687}
bench 9 : {'n_obs': 1000, 'nfeat': 30, 'max_depth': 8, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.08232727775780055, 'time_ort': 0.003556580067827151, 'time_mlprodict': 0.022170927805396225, 'time_mlprodict2': 0.02182657902057354, 'time_mlprodict3': 0.019700800999999046}
bench 10 : {'n_obs': 10000, 'nfeat': 30, 'max_depth': 8, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.10702770799398423, 'time_ort': 0.030052572302520276, 'time_mlprodict': 0.13865551315248012, 'time_mlprodict2': 0.04309481009840965, 'time_mlprodict3': 0.04189431071281433}
bench 11 : {'n_obs': 1, 'nfeat': 30, 'max_depth': 10, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.05514783539662236, 'time_ort': 0.00010079517960548401, 'time_mlprodict': 0.00824174873138729, 'time_mlprodict2': 0.007789983365096544, 'time_mlprodict3': 0.008015583710450875}
bench 12 : {'n_obs': 10, 'nfeat': 30, 'max_depth': 10, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.05737313059055143, 'time_ort': 0.001000885230799516, 'time_mlprodict': 0.0009656976908445358, 'time_mlprodict2': 0.0011074329829878276, 'time_mlprodict3': 0.016058510065906577}
bench 13 : {'n_obs': 100, 'nfeat': 30, 'max_depth': 10, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.06914980423947176, 'time_ort': 0.0015494858225186666, 'time_mlprodict': 0.010059794286886851, 'time_mlprodict2': 0.010474308083454767, 'time_mlprodict3': 0.016736970469355582}
bench 14 : {'n_obs': 1000, 'nfeat': 30, 'max_depth': 10, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.0794465414320047, 'time_ort': 0.005977722601248668, 'time_mlprodict': 0.02757561779939211, 'time_mlprodict2': 0.02897698962344573, 'time_mlprodict3': 0.020387352372591313}
bench 15 : {'n_obs': 10000, 'nfeat': 30, 'max_depth': 10, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.10814805328845978, 'time_ort': 0.04370647370815277, 'time_mlprodict': 0.1910786084830761, 'time_mlprodict2': 0.07201163209974766, 'time_mlprodict3': 0.05348367244005203}
bench 16 : {'n_obs': 1, 'nfeat': 30, 'max_depth': 12, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.05718048423942593, 'time_ort': 0.00010644168489509159, 'time_mlprodict': 0.00390939549025562, 'time_mlprodict2': 0.00028803696235020954, 'time_mlprodict3': 9.197731398873859e-05}
bench 17 : {'n_obs': 10, 'nfeat': 30, 'max_depth': 12, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.05955639119972201, 'time_ort': 0.0011636773672174005, 'time_mlprodict': 0.0012538063832942177, 'time_mlprodict2': 0.0014957304605666328, 'time_mlprodict3': 0.00036632203880478353}
bench 18 : {'n_obs': 100, 'nfeat': 30, 'max_depth': 12, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.06897803073128064, 'time_ort': 0.002500701944033305, 'time_mlprodict': 0.006513191759586335, 'time_mlprodict2': 0.0030381677051385244, 'time_mlprodict3': 0.0020588673651218414}
bench 19 : {'n_obs': 1000, 'nfeat': 30, 'max_depth': 12, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.08466138364747167, 'time_ort': 0.010306961523989836, 'time_mlprodict': 0.02768038958311081, 'time_mlprodict2': 0.03632482405131062, 'time_mlprodict3': 0.018308731727302074}
bench 20 : {'n_obs': 10000, 'nfeat': 30, 'max_depth': 12, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.11488199751410219, 'time_ort': 0.0824148419002692, 'time_mlprodict': 0.23218230447835392, 'time_mlprodict2': 0.10829141487677892, 'time_mlprodict3': 0.05775153429971801}
Total time = 406.643 sec cpu=8
15 16 17 18 19
n_obs 1 10 100 1000 10000
nfeat 30 30 30 30 30
max_depth 12 12 12 12 12
n_estimators 100 100 100 100 100
method predict predict predict predict predict
n_jobs 8 8 8 8 8
time_skl 0.05718 0.059556 0.068978 0.084661 0.114882
time_ort 0.000106 0.001164 0.002501 0.010307 0.082415
time_mlprodict 0.003909 0.001254 0.006513 0.02768 0.232182
time_mlprodict2 0.000288 0.001496 0.003038 0.036325 0.108291
time_mlprodict3 0.000092 0.000366 0.002059 0.018309 0.057752
speedup_ort 537.200104 51.17947 27.583467 8.214 1.393948
speedup_mlprodict 14.626426 47.500469 10.590511 3.058533 0.494792
speedup_mlprodict2 198.51787 39.817596 22.703826 2.330676 1.06086
speedup_mlprodict3 621.680301 162.579329 33.502902 4.624099 1.989246
Total running time of the script: ( 7 minutes 3.140 seconds)