Note
Click here to download the full example code
Compares implementations of ReduceMean#
This example compares the numpy for the operator ReduceMean to onnxruntime implementation. If available, tensorflow and pytorch are included as well.
Available optimisation#
The code shows which parallelisation optimisation could be used, AVX or SSE and the number of available processors.
import numpy
import pandas
import matplotlib.pyplot as plt
from onnxruntime import InferenceSession
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx.algebra.onnx_ops import OnnxReduceMean
from cpyquickhelper.numbers import measure_time
from tqdm import tqdm
from mlprodict.testing.experimental_c_impl.experimental_c import code_optimisation
print(code_optimisation())
Out:
AVX-omp=8
ReduceMean implementations#
try:
from tensorflow.math import reduce_mean as tf_reduce_mean
from tensorflow import convert_to_tensor
except ImportError:
tf_reduce_mean = None
try:
from torch import mean as torch_mean, from_numpy
except ImportError:
torch_mean = None
def build_ort_reducemean(axes, op_version=14): # opset=13, 14, ...
node = OnnxReduceMean('x', axes=axes, op_version=op_version,
output_names=['z'])
onx = node.to_onnx(inputs=[('x', FloatTensorType())],
target_opset=op_version)
sess = InferenceSession(onx.SerializeToString())
return lambda x, y: sess.run(None, {'x': x})
def loop_fct(fct, xs, ys):
for x, y in zip(xs, ys):
fct(x, y)
def benchmark_op(axes, repeat=2, number=5, name="ReduceMean",
shape_fct=None, max_dim=None):
if shape_fct is None:
def shape_fct(dim):
return (3, dim, 1, 128, 64)
ort_fct = build_ort_reducemean(axes)
res = []
for dim in tqdm([4, 8, 16, 32, 64, 100, 128, 200,
256, 400, 512, 1024]):
if max_dim is not None and dim > max_dim:
continue
shape = shape_fct(dim)
n_arrays = 10 if dim < 512 else 4
xs = [numpy.random.rand(*shape).astype(numpy.float32)
for _ in range(n_arrays)]
ys = [numpy.array(axes, dtype=numpy.int64)
for _ in range(n_arrays)]
info = dict(axes=axes, shape=shape)
# numpy
fct = lambda x, y: numpy.mean(x, axis=tuple(y))
ctx = dict(
xs=xs, ys=ys,
loop_fct=loop_fct)
obs = measure_time(
lambda: loop_fct(fct, xs, ys),
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'numpy'
obs.update(info)
res.append(obs)
# onnxruntime
fct = ort_fct
obs = measure_time(
lambda: loop_fct(fct, xs, ys),
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'ort'
obs.update(info)
res.append(obs)
if tf_reduce_mean is not None:
# tensorflow
fct = tf_reduce_mean
ctx['xs'] = [convert_to_tensor(x) for x in xs]
ctx['ys'] = ys
obs = measure_time(
lambda: loop_fct(fct, ctx['xs'], ctx['ys']),
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'tf'
obs.update(info)
res.append(obs)
if torch_mean is not None:
def torch_mean1(x, y):
return torch_mean(x, y[0])
def torch_mean2(x, y):
return torch_mean(torch_mean(x, y[1]), y[0])
# torch
fct = torch_mean1 if len(axes) == 1 else torch_mean2
ctx['xs'] = [from_numpy(x) for x in xs]
ctx['ys'] = ys # [from_numpy(y) for y in ys]
obs = measure_time(
lambda: loop_fct(fct, ctx['xs'], ctx['ys']),
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'torch'
obs.update(info)
res.append(obs)
# Dataframes
shape_name = str(shape).replace(str(dim), "N")
df = pandas.DataFrame(res)
df.columns = [_.replace('dim', 'N') for _ in df.columns]
piv = df.pivot('N', 'fct', 'average')
rs = piv.copy()
for c in ['ort', 'torch', 'tf', 'tf_copy']:
if c in rs.columns:
rs[c] = rs['numpy'] / rs[c]
rs['numpy'] = 1.
# Graphs.
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
piv.plot(logx=True, logy=True, ax=ax[0],
title="%s benchmark\n%r - %r"
" lower better" % (name, shape_name, axes))
ax[0].legend(prop={"size": 9})
rs.plot(logx=True, logy=True, ax=ax[1],
title="%s Speedup, baseline=numpy\n%r - %r"
" higher better" % (name, shape_name, axes))
ax[1].plot([min(rs.index), max(rs.index)], [0.5, 0.5], 'g--')
ax[1].plot([min(rs.index), max(rs.index)], [2., 2.], 'g--')
ax[1].legend(prop={"size": 9})
return df, rs, ax
dfs = []
Reduction on a particular case KR#
Consecutive axis not reduced and consecutive reduced axis are merged. KR means kept axis - reduced axis
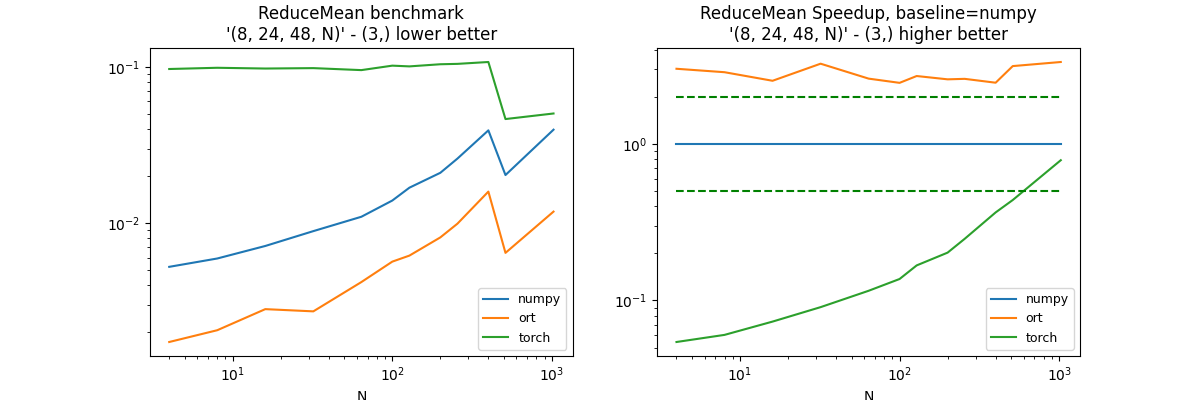
(8, 24, 48, N), axis=(3, )#
axes = (3, )
df, piv, ax = benchmark_op(axes, shape_fct=lambda dim: (8, 24, 48, dim))
dfs.append(df)
df.pivot("fct", "N", "average")
Out:
0%| | 0/12 [00:00<?, ?it/s]
8%|8 | 1/12 [00:01<00:11, 1.05s/it]
17%|#6 | 2/12 [00:02<00:10, 1.08s/it]
25%|##5 | 3/12 [00:03<00:09, 1.10s/it]
33%|###3 | 4/12 [00:04<00:09, 1.14s/it]
42%|####1 | 5/12 [00:05<00:08, 1.20s/it]
50%|##### | 6/12 [00:07<00:07, 1.31s/it]
58%|#####8 | 7/12 [00:08<00:07, 1.41s/it]
67%|######6 | 8/12 [00:10<00:06, 1.58s/it]
75%|#######5 | 9/12 [00:13<00:05, 1.77s/it]
83%|########3 | 10/12 [00:15<00:04, 2.09s/it]
92%|#########1| 11/12 [00:17<00:01, 1.87s/it]
100%|##########| 12/12 [00:19<00:00, 1.98s/it]
100%|##########| 12/12 [00:19<00:00, 1.62s/it]
Reduction on a particular case RK#
Consecutive axis not reduced and consecutive reduced axis are merged. RK means reduced axis - kept axis
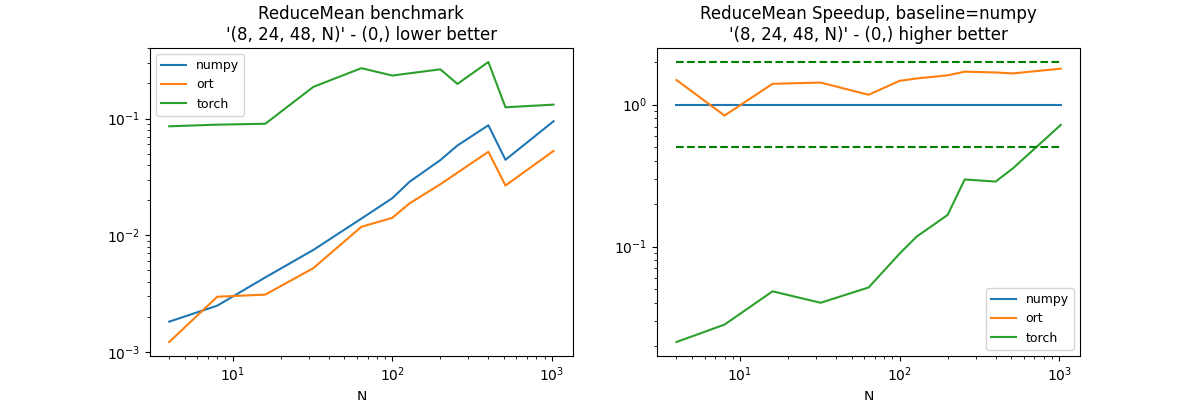
(8, 24, 48, N), axis=(0, )#
axes = (0, )
df, piv, ax = benchmark_op(axes, shape_fct=lambda dim: (8, 24, 48, dim))
dfs.append(df)
df.pivot("fct", "N", "average")
Out:
0%| | 0/12 [00:00<?, ?it/s]
8%|8 | 1/12 [00:00<00:09, 1.11it/s]
17%|#6 | 2/12 [00:01<00:09, 1.06it/s]
25%|##5 | 3/12 [00:02<00:08, 1.02it/s]
33%|###3 | 4/12 [00:05<00:11, 1.42s/it]
42%|####1 | 5/12 [00:08<00:14, 2.05s/it]
50%|##### | 6/12 [00:11<00:14, 2.37s/it]
58%|#####8 | 7/12 [00:14<00:13, 2.68s/it]
67%|######6 | 8/12 [00:18<00:12, 3.09s/it]
75%|#######5 | 9/12 [00:22<00:09, 3.27s/it]
83%|########3 | 10/12 [00:27<00:08, 4.01s/it]
92%|#########1| 11/12 [00:30<00:03, 3.57s/it]
100%|##########| 12/12 [00:34<00:00, 3.71s/it]
100%|##########| 12/12 [00:34<00:00, 2.86s/it]
Reduction on a particular case KRK#
Consecutive axis not reduced and consecutive reduced axis are merged. KRK means kept axis - reduced axis - kept axis,
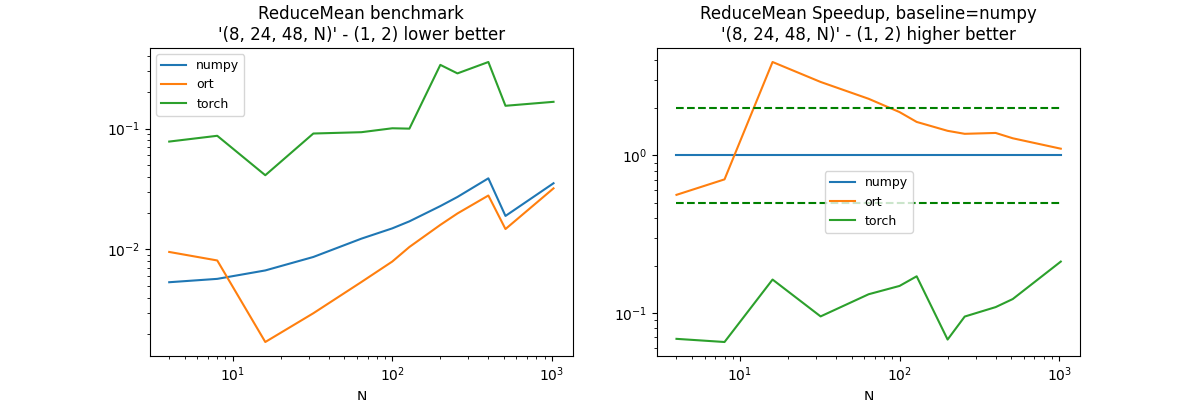
(8, 24, 48, N), axis=(1, 2)#
axes = (1, 2)
df, piv, ax = benchmark_op(axes, shape_fct=lambda dim: (8, 24, 48, dim))
dfs.append(df)
df.pivot("fct", "N", "average")
Out:
0%| | 0/12 [00:00<?, ?it/s]
8%|8 | 1/12 [00:00<00:10, 1.06it/s]
17%|#6 | 2/12 [00:01<00:10, 1.00s/it]
25%|##5 | 3/12 [00:02<00:07, 1.26it/s]
33%|###3 | 4/12 [00:03<00:07, 1.08it/s]
42%|####1 | 5/12 [00:04<00:07, 1.07s/it]
50%|##### | 6/12 [00:06<00:07, 1.23s/it]
58%|#####8 | 7/12 [00:08<00:06, 1.37s/it]
67%|######6 | 8/12 [00:12<00:09, 2.33s/it]
75%|#######5 | 9/12 [00:16<00:08, 2.89s/it]
83%|########3 | 10/12 [00:22<00:07, 3.67s/it]
92%|#########1| 11/12 [00:24<00:03, 3.32s/it]
100%|##########| 12/12 [00:28<00:00, 3.40s/it]
100%|##########| 12/12 [00:28<00:00, 2.35s/it]
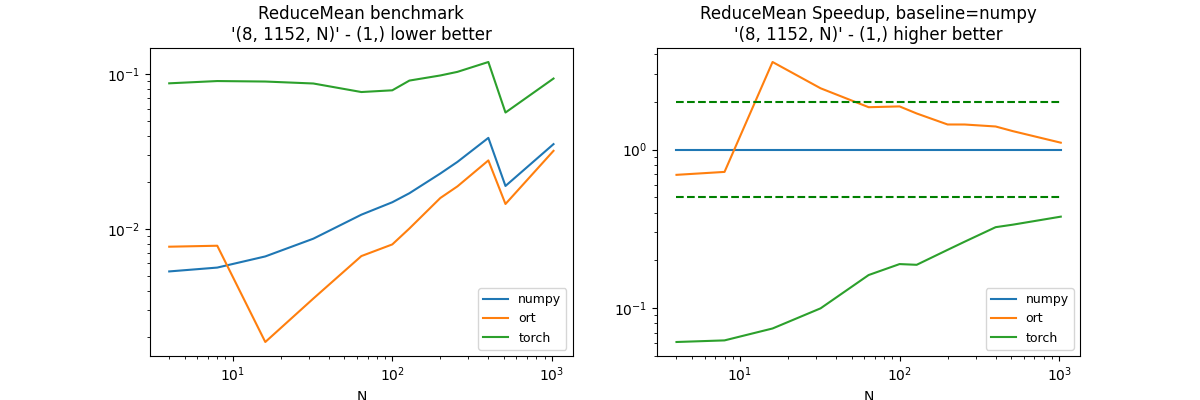
(8, 24 * 48, N), axis=1#
axes = (1, )
df, piv, ax = benchmark_op(axes, shape_fct=lambda dim: (8, 24 * 48, dim))
dfs.append(df)
df.pivot("fct", "N", "average")
Out:
0%| | 0/12 [00:00<?, ?it/s]
8%|8 | 1/12 [00:01<00:11, 1.02s/it]
17%|#6 | 2/12 [00:02<00:10, 1.05s/it]
25%|##5 | 3/12 [00:03<00:09, 1.04s/it]
33%|###3 | 4/12 [00:04<00:08, 1.06s/it]
42%|####1 | 5/12 [00:05<00:07, 1.10s/it]
50%|##### | 6/12 [00:06<00:07, 1.17s/it]
58%|#####8 | 7/12 [00:08<00:06, 1.30s/it]
67%|######6 | 8/12 [00:10<00:06, 1.52s/it]
75%|#######5 | 9/12 [00:12<00:05, 1.75s/it]
83%|########3 | 10/12 [00:15<00:04, 2.16s/it]
92%|#########1| 11/12 [00:17<00:01, 1.96s/it]
100%|##########| 12/12 [00:19<00:00, 2.23s/it]
100%|##########| 12/12 [00:19<00:00, 1.66s/it]
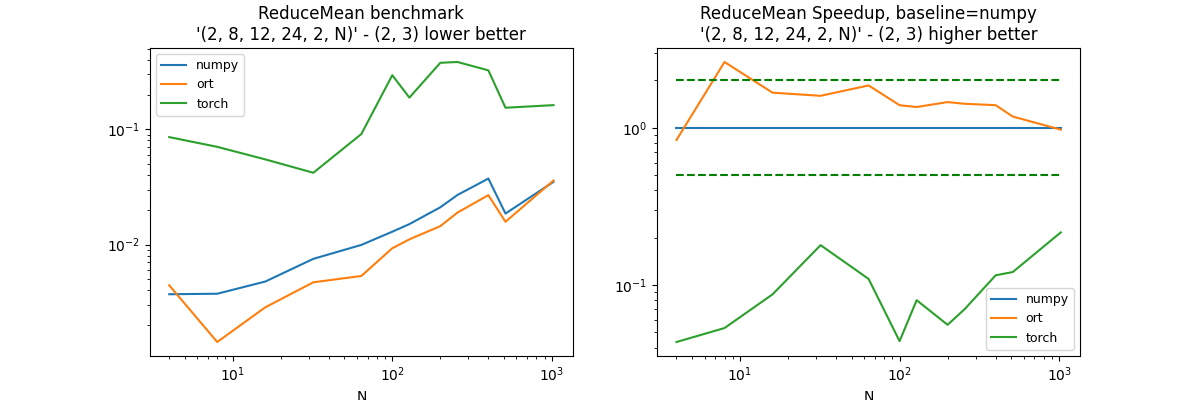
(2, 8, 12, 24, 2, N), axis=(2, 3)#
axes = (2, 3)
df, piv, ax = benchmark_op(axes, shape_fct=lambda dim: (2, 8, 12, 24, 2, dim))
dfs.append(df)
df.pivot("fct", "N", "average")
Out:
0%| | 0/12 [00:00<?, ?it/s]
8%|8 | 1/12 [00:00<00:10, 1.05it/s]
17%|#6 | 2/12 [00:01<00:08, 1.17it/s]
25%|##5 | 3/12 [00:02<00:06, 1.29it/s]
33%|###3 | 4/12 [00:03<00:05, 1.39it/s]
42%|####1 | 5/12 [00:04<00:06, 1.09it/s]
50%|##### | 6/12 [00:07<00:10, 1.79s/it]
58%|#####8 | 7/12 [00:10<00:10, 2.03s/it]
67%|######6 | 8/12 [00:15<00:11, 2.89s/it]
75%|#######5 | 9/12 [00:20<00:10, 3.57s/it]
83%|########3 | 10/12 [00:25<00:08, 4.04s/it]
92%|#########1| 11/12 [00:27<00:03, 3.57s/it]
100%|##########| 12/12 [00:31<00:00, 3.57s/it]
100%|##########| 12/12 [00:31<00:00, 2.61s/it]
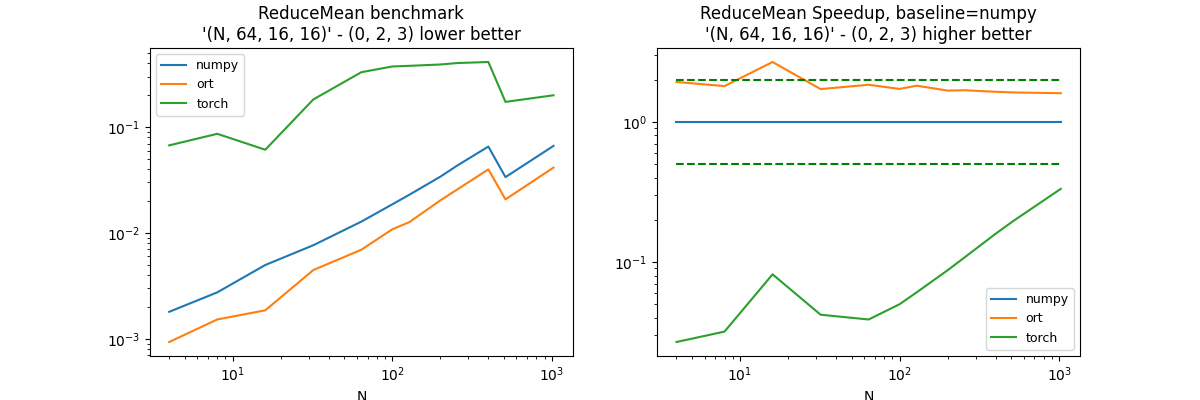
Reduction on a particular case RKR#
(N, 64, 16, 16), axis=(0, 2, 3)#
axes = (0, 2, 3)
df, piv, ax = benchmark_op(
axes, shape_fct=lambda dim: (dim, 64, 16, 16))
dfs.append(df)
df.pivot("fct", "N", "average")
Out:
0%| | 0/12 [00:00<?, ?it/s]
8%|8 | 1/12 [00:00<00:07, 1.38it/s]
17%|#6 | 2/12 [00:01<00:08, 1.16it/s]
25%|##5 | 3/12 [00:02<00:07, 1.22it/s]
33%|###3 | 4/12 [00:04<00:10, 1.33s/it]
42%|####1 | 5/12 [00:08<00:15, 2.24s/it]
50%|##### | 6/12 [00:12<00:18, 3.03s/it]
58%|#####8 | 7/12 [00:17<00:18, 3.62s/it]
67%|######6 | 8/12 [00:23<00:16, 4.23s/it]
75%|#######5 | 9/12 [00:29<00:14, 4.81s/it]
83%|########3 | 10/12 [00:36<00:11, 5.58s/it]
92%|#########1| 11/12 [00:40<00:04, 4.91s/it]
100%|##########| 12/12 [00:45<00:00, 5.02s/it]
100%|##########| 12/12 [00:45<00:00, 3.78s/it]
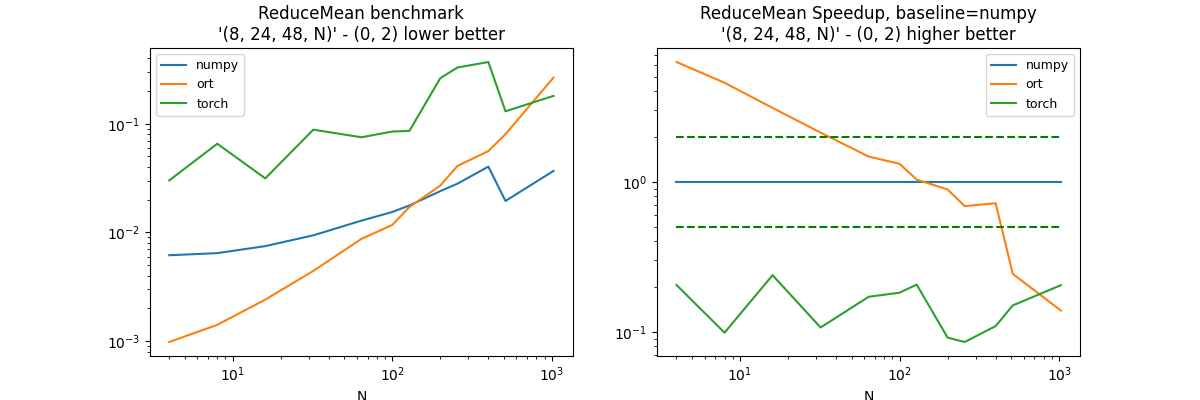
Reduction on a particular case RKRK#
(8, 24, 48, N), axis=(0, 2)#
axes = (0, 2)
df, piv, ax = benchmark_op(axes, shape_fct=lambda dim: (8, 24, 48, dim))
dfs.append(df)
df.pivot("fct", "N", "average")
Out:
0%| | 0/12 [00:00<?, ?it/s]
8%|8 | 1/12 [00:00<00:04, 2.58it/s]
17%|#6 | 2/12 [00:01<00:06, 1.64it/s]
25%|##5 | 3/12 [00:01<00:04, 1.84it/s]
33%|###3 | 4/12 [00:02<00:06, 1.30it/s]
42%|####1 | 5/12 [00:03<00:06, 1.09it/s]
50%|##### | 6/12 [00:05<00:06, 1.09s/it]
58%|#####8 | 7/12 [00:06<00:06, 1.25s/it]
67%|######6 | 8/12 [00:10<00:08, 2.05s/it]
75%|#######5 | 9/12 [00:15<00:08, 2.89s/it]
83%|########3 | 10/12 [00:21<00:07, 3.81s/it]
92%|#########1| 11/12 [00:24<00:03, 3.54s/it]
100%|##########| 12/12 [00:30<00:00, 4.31s/it]
100%|##########| 12/12 [00:30<00:00, 2.52s/it]
Conclusion#
Some of the configurations should be investigated. l-reducesum-problem1. The reduction on tensorflow in one dimension seems to be lazy.
merged = pandas.concat(dfs)
name = "reducemean"
merged.to_csv("plot_%s.csv" % name, index=False)
merged.to_excel("plot_%s.xlsx" % name, index=False)
plt.savefig("plot_%s.png" % name)
plt.show()

Total running time of the script: ( 3 minutes 46.734 seconds)