Note
Click here to download the full example code
TreeEnsembleRegressor and parallelisation#
The operator TreeEnsembleClassifier describe any tree model (decision tree, random forest, gradient boosting). The runtime is usually implements in C/C++ and uses parallelisation. The notebook studies the impact of the parallelisation.
:local
Graph#
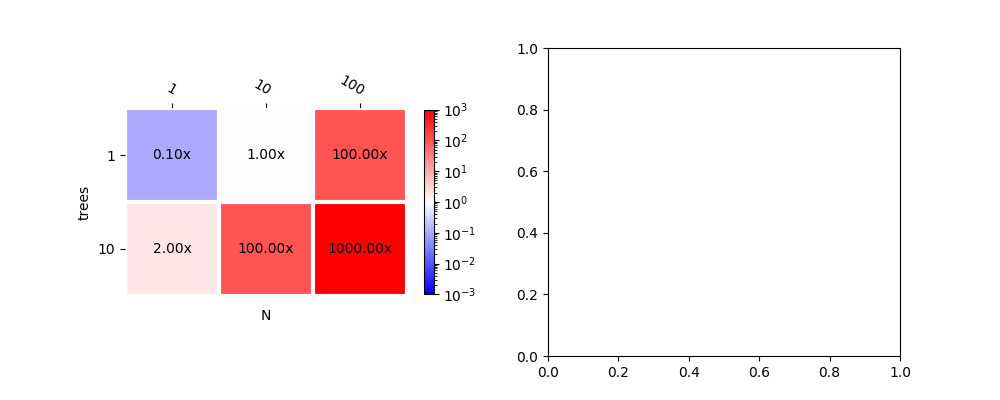
The following dummy graph shows the time ratio between two runtimes depending on the number of observations in a batch (N) and the number of trees in the forest.
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from mlprodict.onnxrt import OnnxInference
from onnxruntime import InferenceSession
from skl2onnx import to_onnx
from mlprodict.onnxrt.validate.validate_benchmark import benchmark_fct
import sklearn
import numpy
from tqdm import tqdm
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
from mlprodict.plotting.plotting import plot_benchmark_metrics
def plot_metric(metric, ax=None, xlabel="N", ylabel="trees", middle=1.,
transpose=False, shrink=1.0, title=None, figsize=None):
if figsize is not None and ax is None:
_, ax = plt.subplots(1, 1, figsize=figsize)
ax, cbar = plot_benchmark_metrics(
metric, ax=ax, xlabel=xlabel, ylabel=ylabel, middle=middle,
transpose=transpose, cbar_kw={'shrink': shrink})
if title is not None:
ax.set_title(title)
return ax
data = {(1, 1): 0.1, (10, 1): 1, (1, 10): 2,
(10, 10): 100, (100, 1): 100, (100, 10): 1000}
fig, ax = plt.subplots(1, 2, figsize=(10, 4))
plot_metric(data, ax[0], shrink=0.6)
Out:
<AxesSubplot:xlabel='N', ylabel='trees'>
plot_metric(data, ax[1], transpose=True)
Out:
<AxesSubplot:xlabel='trees', ylabel='N'>
scikit-learn: T trees vs 1 tree#
Let’s do first compare a GradientBoostingClassifier from scikit-learn with 1 tree against multiple trees.
# In[4]:
ntest = 10000
X, y = make_classification(
n_samples=10000 + ntest, n_features=10, n_informative=5,
n_classes=2, random_state=11)
X_train, X_test, y_train, y_test = X[:-
ntest], X[-ntest:], y[:-ntest], y[-ntest:]
ModelToTest = GradientBoostingClassifier
N = [1, 10, 100, 1000, 10000]
T = [1, 2, 10, 20, 50]
models = {}
for nt in tqdm(T):
rf = ModelToTest(n_estimators=nt, max_depth=7).fit(X_train, y_train)
models[nt] = rf
Out:
0%| | 0/5 [00:00<?, ?it/s]
20%|## | 1/5 [00:00<00:00, 4.04it/s]
40%|#### | 2/5 [00:00<00:00, 3.01it/s]
60%|###### | 3/5 [00:02<00:02, 1.08s/it]
80%|######## | 4/5 [00:06<00:02, 2.19s/it]
100%|##########| 5/5 [00:16<00:00, 4.93s/it]
100%|##########| 5/5 [00:16<00:00, 3.26s/it]
Benchmark.
def benchmark(X, fct1, fct2, N, repeat=10, number=20):
def ti(r, n):
if n <= 1:
return 40 * r
if n <= 10:
return 10 * r
if n <= 100:
return 4 * r
if n <= 1000:
return r
return r // 2
with sklearn.config_context(assume_finite=True):
# to warm up the engine
time_kwargs = {n: dict(repeat=10, number=10) for n in N}
benchmark_fct(fct1, X, time_kwargs=time_kwargs, skip_long_test=False)
benchmark_fct(fct2, X, time_kwargs=time_kwargs, skip_long_test=False)
# real measure
time_kwargs = {n: dict(repeat=ti(repeat, n), number=number) for n in N}
res1 = benchmark_fct(
fct1, X, time_kwargs=time_kwargs, skip_long_test=False)
res2 = benchmark_fct(
fct2, X, time_kwargs=time_kwargs, skip_long_test=False)
res = {}
for r in sorted(res1):
r1 = res1[r]
r2 = res2[r]
ratio = r2['ttime'] / r1['ttime']
res[r] = ratio
return res
def tree_benchmark(X, fct1, fct2, T, N, repeat=20, number=10):
bench = {}
for t in tqdm(T):
if callable(X):
x = X(t)
else:
x = X
r = benchmark(x, fct1(t), fct2(t), N, repeat=repeat, number=number)
for n, v in r.items():
bench[n, t] = v
return bench
bench = tree_benchmark(X_test.astype(numpy.float32),
lambda t: models[1].predict,
lambda t: models[t].predict, T, N)
list(bench.items())[:3]
Out:
0%| | 0/5 [00:00<?, ?it/s]
20%|## | 1/5 [00:19<01:19, 20.00s/it]
40%|#### | 2/5 [00:40<01:00, 20.11s/it]
60%|###### | 3/5 [01:02<00:41, 20.91s/it]
80%|######## | 4/5 [01:25<00:22, 22.09s/it]
100%|##########| 5/5 [01:55<00:00, 24.93s/it]
100%|##########| 5/5 [01:55<00:00, 23.18s/it]
[((1, 1), 0.9986346594803491), ((10, 1), 1.000348395535168), ((100, 1), 0.9953942470338755)]
Graph.
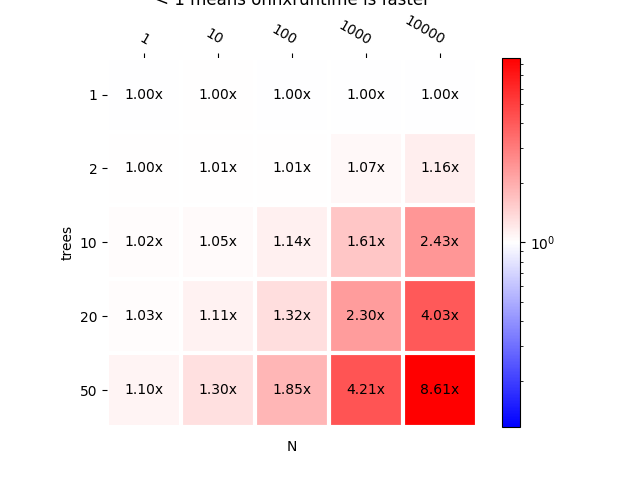
plot_metric(bench, title="scikit-learn 1 tree vs scikit-learn T trees\n"
"< 1 means onnxruntime is faster")
Out:
<AxesSubplot:title={'center':'scikit-learn 1 tree vs scikit-learn T trees\n< 1 means onnxruntime is faster'}, xlabel='N', ylabel='trees'>
As expected, all ratio on first line are close to 1 since both models are the same. fourth line, second column (T=20, N=10) means an ensemble with 20 trees is slower to compute the predictions of 10 observations in a batch compare to an ensemble with 1 tree.
scikit-learn against onnxuntime#
X32 = X_test.astype(numpy.float32)
models_onnx = {t: to_onnx(m, X32[:1]) for t, m in models.items()}
sess_models = {t: InferenceSession(mo.SerializeToString())
for t, mo in models_onnx.items()}
Out:
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
Benchmark.
bench_ort = tree_benchmark(
X_test.astype(numpy.float32),
lambda t: models[t].predict_proba,
lambda t: (lambda x, t_=t, se=sess_models: se[t_].run(None, {'X': x})),
T, N)
bench_ort
Out:
0%| | 0/5 [00:00<?, ?it/s]
20%|## | 1/5 [00:14<00:58, 14.63s/it]
40%|#### | 2/5 [00:29<00:44, 14.72s/it]
60%|###### | 3/5 [00:47<00:32, 16.48s/it]
80%|######## | 4/5 [01:09<00:18, 18.36s/it]
100%|##########| 5/5 [01:38<00:00, 22.16s/it]
100%|##########| 5/5 [01:38<00:00, 19.62s/it]
{(1, 1): 0.10745178393859103, (10, 1): 0.1256487018625591, (100, 1): 0.29413061224778636, (1000, 1): 1.6953830253872568, (10000, 1): 4.032696513588496, (1, 2): 0.10744041580390046, (10, 2): 0.12590478688372522, (100, 2): 0.29170841342254894, (1000, 2): 1.484850040782813, (10000, 2): 3.4800833828932674, (1, 10): 0.10758366939113244, (10, 10): 0.13529648705810318, (100, 10): 0.36767012043859787, (1000, 10): 1.422193360543461, (10000, 10): 2.3391630275591915, (1, 20): 0.10428142041137484, (10, 20): 0.14255817207527216, (100, 20): 0.33343341282251443, (1000, 20): 1.0493064866002648, (10000, 20): 1.5011176183922992, (1, 50): 0.11016883954942784, (10, 50): 0.18400158144509643, (100, 50): 0.2815831611285774, (1000, 50): 0.6971730823072282, (10000, 50): 0.8666282364382145}
Graphs
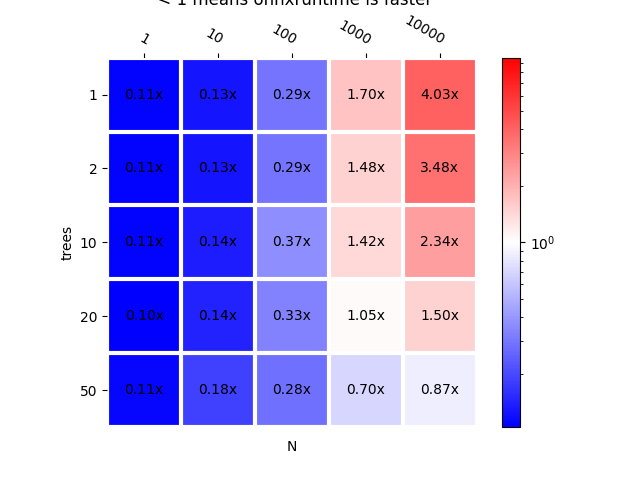
plot_metric(bench_ort, title="scikit-learn vs onnxruntime\n < 1 "
"means onnxruntime is faster")
Out:
<AxesSubplot:title={'center':'scikit-learn vs onnxruntime\n < 1 means onnxruntime is faster'}, xlabel='N', ylabel='trees'>
We see onnxruntime is fast for small batches, still faster but not that much for big batches.
ZipMap operator#
ZipMap just creates a new container for the same results. The copy may impact the ratio. Let’s remove it from the equation.
X32 = X_test.astype(numpy.float32)
models_onnx = {t: to_onnx(m, X32[:1],
options={ModelToTest: {'zipmap': False}})
for t, m in models.items()}
sess_models = {t: InferenceSession(mo.SerializeToString())
for t, mo in models_onnx.items()}
Out:
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: Attribute `n_features_` was deprecated in version 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: Attribute `n_features_` was deprecated in version 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: Attribute `n_features_` was deprecated in version 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: Attribute `n_features_` was deprecated in version 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: Attribute `n_features_` was deprecated in version 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
Benchmarks.
bench_ort = tree_benchmark(
X_test.astype(numpy.float32),
lambda t: models[t].predict_proba,
lambda t: (lambda x, t_=t, se=sess_models: se[t_].run(None, {'X': x})),
T, N)
bench_ort
Out:
0%| | 0/5 [00:00<?, ?it/s]
20%|## | 1/5 [00:10<00:42, 10.60s/it]
40%|#### | 2/5 [00:21<00:32, 10.72s/it]
60%|###### | 3/5 [00:36<00:25, 12.94s/it]
80%|######## | 4/5 [00:55<00:15, 15.20s/it]
100%|##########| 5/5 [01:23<00:00, 19.72s/it]
100%|##########| 5/5 [01:23<00:00, 16.68s/it]
{(1, 1): 0.09448585496807024, (10, 1): 0.09680629838045533, (100, 1): 0.1086254445101944, (1000, 1): 0.13076143912242422, (10000, 1): 0.18556890807081175, (1, 2): 0.09546326780205351, (10, 2): 0.09934692834764017, (100, 2): 0.10988399373426447, (1000, 2): 0.1401014902356618, (10000, 2): 0.20053310240312405, (1, 10): 0.09573671018544877, (10, 10): 0.10765394426949626, (100, 10): 0.22601054707765633, (1000, 10): 0.7083486281715143, (10000, 10): 1.3244542258030654, (1, 20): 0.09824032456639578, (10, 20): 0.1261986422444393, (100, 20): 0.2208451197123215, (1000, 20): 0.5895464854602973, (10000, 20): 0.9699684044278726, (1, 50): 0.09893464607695, (10, 50): 0.16489086298393657, (100, 50): 0.20215065869758628, (1000, 50): 0.47934368522142734, (10000, 50): 0.7979746960526732}
Graphs.
plot_metric(bench_ort, title="scikit-learn vs onnxruntime (no zipmap)\n < 1 "
"means onnxruntime is faster")
# ZipMap removal significantly improves.
#
# Implementation details for mlprodict runtime
# ++++++++++++++++++++++++++++++++++++++++++++
#
# The runtime implemented in :epkg:`mlprodict` mostly relies on
# two files:
# * `op_tree_ensemble_common_p_agg_.hpp <https://github.com/sdpython/
# mlprodict/blob/master/mlprodict/onnxrt/ops_cpu/
# op_tree_ensemble_common_p_agg_.hpp>`_
# * `op_tree_ensemble_common_p_.hpp <https://github.com/sdpython/
# mlprodict/blob/master/mlprodict/onnxrt/ops_cpu/
# op_tree_ensemble_common_p_.hpp>`_
#
# The runtime builds a tree structure, computes the output of every
# tree and then agregates them. The implementation distringuishes
# when the batch size contains only 1 observations or many.
# It parallelizes on the following conditions:
# * if the batch size $N \geqslant N_0$, it then parallelizes per
# observation, asuming every one is independant,
# * if the batch size $N = 1$ and the number of trees
# $T \geqslant T_0$, it then parallelizes per tree.
#
# scikit-learn against mlprodict, no parallelisation
# ++++++++++++++++++++++++++++++++++++++++++++++++++
oinf_models = {t: OnnxInference(mo, runtime="python_compiled")
for t, mo in models_onnx.items()}
Let’s modify the thresholds which trigger the parallelization.
for _, oinf in oinf_models.items():
oinf.sequence_[0].ops_.rt_.omp_tree_ = 10000000
oinf.sequence_[0].ops_.rt_.omp_N_ = 10000000
Benchmarks.
bench_mlp = tree_benchmark(
X_test.astype(numpy.float32),
lambda t: models[t].predict,
lambda t: (lambda x, t_=t, oi=oinf_models: oi[t_].run({'X': x})),
T, N)
bench_mlp
Out:
0%| | 0/5 [00:00<?, ?it/s]
20%|## | 1/5 [00:11<00:44, 11.14s/it]
40%|#### | 2/5 [00:22<00:34, 11.44s/it]
60%|###### | 3/5 [00:39<00:27, 13.87s/it]
80%|######## | 4/5 [01:04<00:18, 18.33s/it]
100%|##########| 5/5 [01:52<00:00, 28.80s/it]
100%|##########| 5/5 [01:52<00:00, 22.42s/it]
{(1, 1): 0.05329692893325514, (10, 1): 0.05675549243774483, (100, 1): 0.08190704401532897, (1000, 1): 0.2509185221791713, (10000, 1): 0.5758854139504826, (1, 2): 0.05380513713478591, (10, 2): 0.05874436307533113, (100, 2): 0.09688898182849806, (1000, 2): 0.33408298746375353, (10000, 2): 0.7422296249181807, (1, 10): 0.05523086375486625, (10, 10): 0.07453834356955792, (100, 10): 0.23259609953138785, (1000, 10): 0.9208734744788102, (10000, 10): 1.584152428328549, (1, 20): 0.057772998091162646, (10, 20): 0.10046896484506097, (100, 20): 0.4341042503452291, (1000, 20): 1.5778107871275282, (10000, 20): 2.3569039980967648, (1, 50): 0.06196149473842815, (10, 50): 0.1509092455449356, (100, 50): 0.753463587766876, (1000, 50): 2.1547253679182083, (10000, 50): 2.7640603996695576}
Graphs.
plot_metric(bench_mlp, title="scikit-learn vs mlprodict\n < 1 "
"means mlprodict is faster")
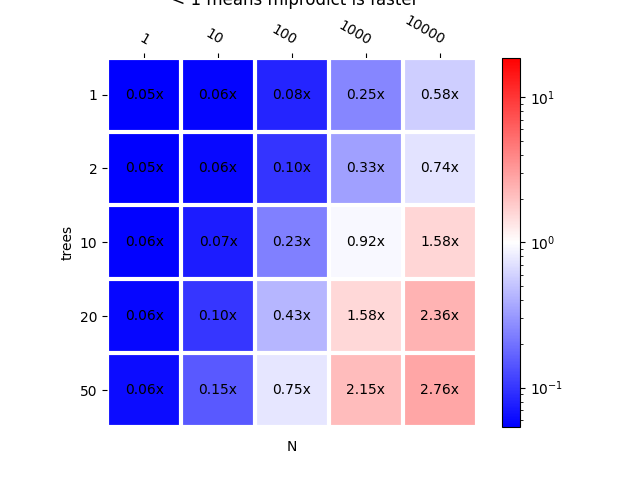
Out:
<AxesSubplot:title={'center':'scikit-learn vs mlprodict\n < 1 means mlprodict is faster'}, xlabel='N', ylabel='trees'>
Let’s compare onnxruntime against mlprodict.
bench_mlp_ort = tree_benchmark(
X_test.astype(numpy.float32),
lambda t: (lambda x, t_=t, se=sess_models: se[t_].run(None, {'X': x})),
lambda t: (lambda x, t_=t, oi=oinf_models: oi[t_].run({'X': x})),
T, N)
bench_mlp_ort
Out:
0%| | 0/5 [00:00<?, ?it/s]
20%|## | 1/5 [00:02<00:08, 2.17s/it]
40%|#### | 2/5 [00:04<00:07, 2.39s/it]
60%|###### | 3/5 [00:13<00:10, 5.22s/it]
80%|######## | 4/5 [00:29<00:09, 9.36s/it]
100%|##########| 5/5 [01:03<00:00, 18.28s/it]
100%|##########| 5/5 [01:03<00:00, 12.62s/it]
{(1, 1): 0.5893220349658057, (10, 1): 0.6091144541739735, (100, 1): 0.799607569656932, (1000, 1): 1.9743801671925296, (10000, 1): 3.338903562471071, (1, 2): 0.5896201485969849, (10, 2): 0.6185937183262247, (100, 2): 0.9270005048626073, (1000, 2): 2.4478991448646537, (10000, 2): 3.9250607016427903, (1, 10): 0.6050932584241883, (10, 10): 0.7300578978767085, (100, 10): 1.002636769457864, (1000, 10): 1.2660143076945343, (10000, 10): 1.5465692143183956, (1, 20): 0.612390100030294, (10, 20): 0.8200480084381241, (100, 20): 1.9615852137989758, (1000, 20): 2.6249647447595255, (10000, 20): 3.1442932008400404, (1, 50): 0.6586467254103388, (10, 50): 0.949798122254939, (100, 50): 3.776302713547626, (1000, 50): 4.486289172842603, (10000, 50): 4.755620292876148}
Graphs.
plot_metric(bench_mlp_ort, title="onnxruntime vs mlprodict\n < 1 means "
"mlprodict is faster\nno parallelisation")
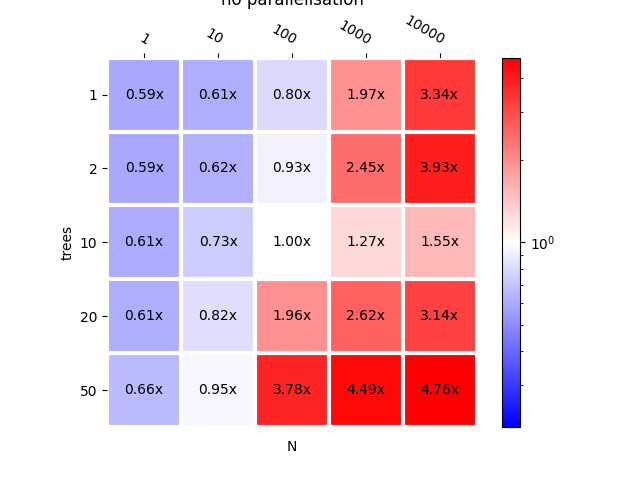
Out:
<AxesSubplot:title={'center':'onnxruntime vs mlprodict\n < 1 means mlprodict is faster\nno parallelisation'}, xlabel='N', ylabel='trees'>
This implementation is faster except for high number of trees or high number of observations. Let’s add parallelisation for trees and observations.
for _, oinf in oinf_models.items():
oinf.sequence_[0].ops_.rt_.omp_tree_ = 2
oinf.sequence_[0].ops_.rt_.omp_N_ = 2
bench_mlp_para = tree_benchmark(
X_test.astype(numpy.float32),
lambda t: models[t].predict,
lambda t: (lambda x, t_=t, oi=oinf_models: oi[t_].run({'X': x})),
T, N)
bench_mlp_para
Out:
0%| | 0/5 [00:00<?, ?it/s]
20%|## | 1/5 [00:26<01:46, 26.62s/it]
40%|#### | 2/5 [00:39<00:55, 18.64s/it]
60%|###### | 3/5 [00:56<00:35, 17.99s/it]
80%|######## | 4/5 [01:33<00:25, 25.32s/it]
100%|##########| 5/5 [02:02<00:00, 26.82s/it]
100%|##########| 5/5 [02:02<00:00, 24.59s/it]
{(1, 1): 0.05286871725977243, (10, 1): 6.8836192627013215, (100, 1): 2.7051826256812928, (1000, 1): 6.304531775674716, (10000, 1): 2.0916781266975106, (1, 2): 0.052174800194003466, (10, 2): 0.4245193600347045, (100, 2): 0.10330737665213013, (1000, 2): 0.3586718578098879, (10000, 2): 0.8727501553849253, (1, 10): 0.3595197561363624, (10, 10): 0.16090001446710764, (100, 10): 0.09803245947425539, (1000, 10): 0.2987561432191349, (10000, 10): 0.4609569282263275, (1, 20): 2.6150459890946913, (10, 20): 0.19568565239752297, (100, 20): 0.12870933213942387, (1000, 20): 3.315357407201718, (10000, 20): 1.1539759293315635, (1, 50): 0.16129516649014652, (10, 50): 0.2131711372693617, (100, 50): 0.09535758502926563, (1000, 50): 0.1687201599858167, (10000, 50): 0.40372385889738516}
Graphs.
plot_metric(bench_mlp_para, title="scikit-learn vs mlprodict\n < 1 means "
"mlprodict is faster\nparallelisation")
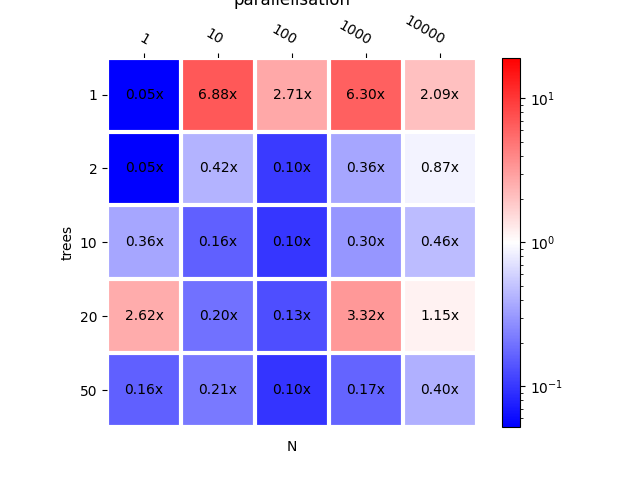
Out:
<AxesSubplot:title={'center':'scikit-learn vs mlprodict\n < 1 means mlprodict is faster\nparallelisation'}, xlabel='N', ylabel='trees'>
Parallelisation does improve the computation time when N is big. Let’s compare with and without parallelisation.
bench_para = {}
for k, v in bench_mlp.items():
bench_para[k] = bench_mlp_para[k] / v
plot_metric(bench_para, title="mlprodict vs mlprodict parallelized\n < 1 "
"means parallelisation is faster")
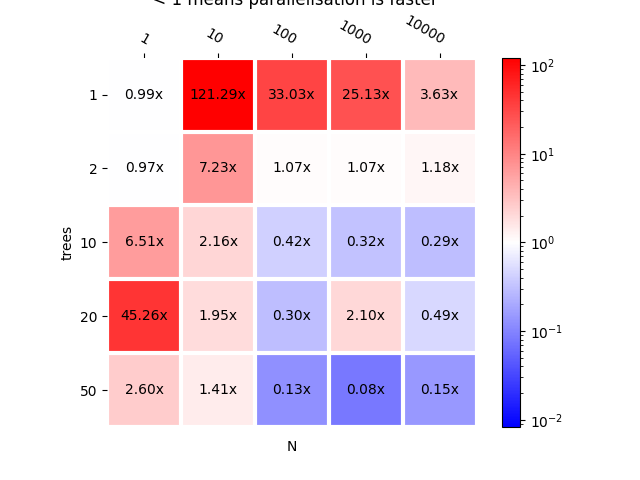
Out:
<AxesSubplot:title={'center':'mlprodict vs mlprodict parallelized\n < 1 means parallelisation is faster'}, xlabel='N', ylabel='trees'>
Parallelisation per trees does not seem to be efficient. Let’s confirm with a proper benchmark as the previous merges results from two benchmarks.
for _, oinf in oinf_models.items():
oinf.sequence_[0].ops_.rt_.omp_tree_ = 1000000
oinf.sequence_[0].ops_.rt_.omp_N_ = 1000000
oinf_models_para = {t: OnnxInference(mo, runtime="python_compiled")
for t, mo in models_onnx.items()}
for _, oinf in oinf_models_para.items():
oinf.sequence_[0].ops_.rt_.omp_tree_ = 2
oinf.sequence_[0].ops_.rt_.omp_N_ = 2
bench_mlp_para = tree_benchmark(
X_test.astype(numpy.float32),
lambda t: (lambda x, t_=t, oi=oinf_models: oi[t_].run({'X': x})),
lambda t: (lambda x, t_=t, oi=oinf_models_para: oi[t_].run({'X': x})),
T, N, repeat=20, number=20)
bench_mlp_para
Out:
0%| | 0/5 [00:00<?, ?it/s]
20%|## | 1/5 [00:04<00:17, 4.41s/it]
40%|#### | 2/5 [00:08<00:13, 4.49s/it]
60%|###### | 3/5 [00:55<00:47, 23.58s/it]
80%|######## | 4/5 [01:57<00:38, 38.85s/it]
100%|##########| 5/5 [03:32<00:00, 59.26s/it]
100%|##########| 5/5 [03:32<00:00, 42.59s/it]
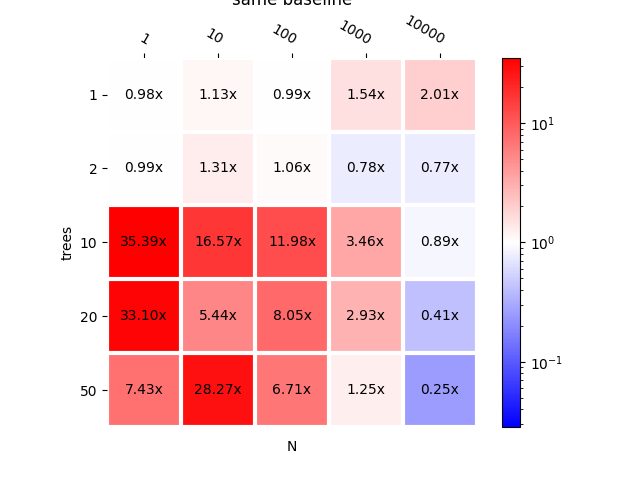
{(1, 1): 0.9814702851892596, (10, 1): 1.1349809875819972, (100, 1): 0.9928452023622985, (1000, 1): 1.5350526512192995, (10000, 1): 2.0063667621480037, (1, 2): 0.9892314395486872, (10, 2): 1.3110492684869148, (100, 2): 1.0643268572542968, (1000, 2): 0.775216557780646, (10000, 2): 0.766604287210717, (1, 10): 35.394059324241304, (10, 10): 16.57050981321819, (100, 10): 11.983899401663496, (1000, 10): 3.458439234031079, (10000, 10): 0.8939209045641269, (1, 20): 33.10061949008491, (10, 20): 5.438875785025879, (100, 20): 8.046452732596087, (1000, 20): 2.928817399089297, (10000, 20): 0.41489277928307733, (1, 50): 7.43391352441265, (10, 50): 28.26673777663611, (100, 50): 6.7056847453653265, (1000, 50): 1.2518029586030024, (10000, 50): 0.25191224661408457}
Graph.
plot_metric(bench_mlp_para, title="mlprodict vs mlprodict parallelized\n < 1 "
"means parallelisation is faster\nsame baseline")
Out:
<AxesSubplot:title={'center':'mlprodict vs mlprodict parallelized\n < 1 means parallelisation is faster\nsame baseline'}, xlabel='N', ylabel='trees'>
It should be run on different machines. On the current one, parallelisation per trees (when N=1) does not seem to help. Parallelisation for a small number of observations does not seem to help either. So we need to find some threshold.
Parallelisation per trees#
Let’s study the parallelisation per tree. We need to train new models.
# In[33]:
N2 = [1, 10]
T2 = [1, 2, 10, 50, 100, 150, 200, 300, 400, 500]
models2 = {}
for nt in tqdm(T2):
rf = ModelToTest(n_estimators=nt, max_depth=7).fit(X_train, y_train)
models2[nt] = rf
Out:
0%| | 0/10 [00:00<?, ?it/s]
10%|# | 1/10 [00:00<00:01, 5.08it/s]
20%|## | 2/10 [00:00<00:02, 3.20it/s]
30%|### | 3/10 [00:02<00:07, 1.07s/it]
40%|#### | 4/10 [00:12<00:26, 4.49s/it]
50%|##### | 5/10 [00:31<00:49, 9.89s/it]
60%|###### | 6/10 [01:00<01:05, 16.43s/it]
70%|####### | 7/10 [01:39<01:11, 23.75s/it]
80%|######## | 8/10 [02:37<01:09, 34.67s/it]
90%|######### | 9/10 [03:55<00:47, 47.99s/it]
100%|##########| 10/10 [05:31<00:00, 62.96s/it]
100%|##########| 10/10 [05:31<00:00, 33.15s/it]
Conversion to ONNX.
X32 = X_test.astype(numpy.float32)
models2_onnx = {t: to_onnx(m, X32[:1]) for t, m in models2.items()}
oinf_models2 = {t: OnnxInference(mo, runtime="python_compiled")
for t, mo in models2_onnx.items()}
for _, oinf in oinf_models2.items():
oinf.sequence_[0].ops_.rt_.omp_tree_ = 1000000
oinf.sequence_[0].ops_.rt_.omp_N_ = 1000000
oinf_models2_para = {t: OnnxInference(
mo, runtime="python_compiled") for t, mo in models2_onnx.items()}
for _, oinf in oinf_models2_para.items():
oinf.sequence_[0].ops_.rt_.omp_tree_ = 2
oinf.sequence_[0].ops_.rt_.omp_N_ = 100
Out:
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
/var/lib/jenkins/workspace/mlprodict/mlprodict_UT_39_std/_venv/lib/python3.9/site-packages/sklearn/utils/deprecation.py:103: FutureWarning: The attribute `n_features_` is deprecated in 1.0 and will be removed in 1.2. Use `n_features_in_` instead.
warnings.warn(msg, category=FutureWarning)
And benchmark.
# In[36]:
bench_mlp_tree = tree_benchmark(
X_test.astype(numpy.float32),
lambda t: (lambda x, t_=t, oi=oinf_models2: oi[t_].run({'X': x})),
lambda t: (lambda x, t_=t, oi=oinf_models2_para: oi[t_].run({'X': x})),
T2, N2, repeat=20, number=20)
bench_mlp_tree
Out:
0%| | 0/10 [00:00<?, ?it/s]
10%|# | 1/10 [00:02<00:22, 2.51s/it]
20%|## | 2/10 [00:05<00:20, 2.53s/it]
30%|### | 3/10 [00:08<00:19, 2.85s/it]
40%|#### | 4/10 [00:12<00:19, 3.27s/it]
50%|##### | 5/10 [00:16<00:18, 3.77s/it]
60%|###### | 6/10 [00:22<00:17, 4.40s/it]
70%|####### | 7/10 [00:29<00:16, 5.34s/it]
80%|######## | 8/10 [00:42<00:15, 7.66s/it]
90%|######### | 9/10 [01:02<00:11, 11.68s/it]
100%|##########| 10/10 [01:30<00:00, 16.59s/it]
100%|##########| 10/10 [01:30<00:00, 9.05s/it]
{(1, 1): 0.9927936818905806, (10, 1): 0.9968264695530976, (1, 2): 0.9923687561932233, (10, 2): 1.0011225234290904, (1, 10): 1.4462865381872163, (10, 10): 1.2054182092411687, (1, 50): 1.3939569791705835, (10, 50): 0.5026028687581705, (1, 100): 1.2273188849034524, (10, 100): 0.5754709138694123, (1, 150): 1.1056823249565848, (10, 150): 0.33073248697201924, (1, 200): 0.9600105168154409, (10, 200): 0.21742443723986216, (1, 300): 0.5424269336138723, (10, 300): 0.1262200263139531, (1, 400): 0.33475411810238914, (10, 400): 0.0982592992181812, (1, 500): 0.24573234555118537, (10, 500): 0.08573930289168043}
Graph.
plot_metric(
bench_mlp_tree, transpose=True, figsize=(10, 3), shrink=0.5,
title="mlprodict vs mlprodict parallelized\n < 1 means parallelisation "
"is faster")
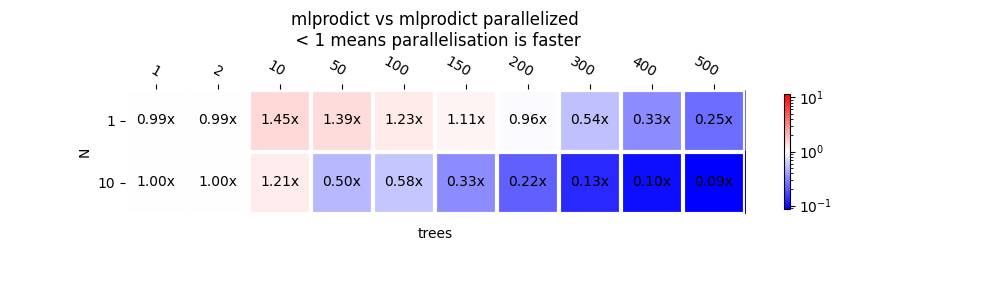
Out:
<AxesSubplot:title={'center':'mlprodict vs mlprodict parallelized\n < 1 means parallelisation is faster'}, xlabel='trees', ylabel='N'>
The parallelisation starts to be below 1 after 400 trees. For 10 observations, there is no parallelisation neither by trees nor by observations. Ratios are close to 1. The gain obviously depends on the tree depth. You can try with a different max depth and the number of trees parallelisation becomes interesting depending on the tree depth.
Multi-Class DecisionTreeClassifier#
Same experiment when the number of tree is 1 but then we change the number of classes.
ModelToTest = DecisionTreeClassifier
C = [2, 5, 10, 15, 20, 30, 40, 50]
N = [1, 10, 100, 1000, 10000]
trees = {}
for cl in tqdm(C):
ntest = 10000
X, y = make_classification(
n_samples=10000 + ntest, n_features=12, n_informative=8,
n_classes=cl, random_state=11)
X_train, X_test, y_train, y_test = (
X[:-ntest], X[-ntest:], y[:-ntest], y[-ntest:])
dt = ModelToTest(max_depth=7).fit(X_train, y_train)
X32 = X_test.astype(numpy.float32)
monnx = to_onnx(dt, X32[:1])
oinf = OnnxInference(monnx)
oinf.sequence_[0].ops_.rt_.omp_N_ = 1000000
trees[cl] = dict(model=dt, X_test=X_test, X32=X32, monnx=monnx, oinf=oinf)
bench_dt = tree_benchmark(lambda cl: trees[cl]['X32'],
lambda cl: trees[cl]['model'].predict_proba,
lambda cl: (
lambda x, c=cl: trees[c]['oinf'].run({'X': x})),
C, N)
bench_dt
Out:
0%| | 0/8 [00:00<?, ?it/s]
12%|#2 | 1/8 [00:00<00:02, 2.58it/s]
25%|##5 | 2/8 [00:00<00:02, 2.51it/s]
38%|###7 | 3/8 [00:01<00:02, 2.35it/s]
50%|##### | 4/8 [00:01<00:01, 2.20it/s]
62%|######2 | 5/8 [00:02<00:01, 2.05it/s]
75%|#######5 | 6/8 [00:02<00:01, 1.84it/s]
88%|########7 | 7/8 [00:03<00:00, 1.64it/s]
100%|##########| 8/8 [00:04<00:00, 1.48it/s]
100%|##########| 8/8 [00:04<00:00, 1.77it/s]
0%| | 0/8 [00:00<?, ?it/s]
12%|#2 | 1/8 [00:05<00:38, 5.48s/it]
25%|##5 | 2/8 [00:11<00:34, 5.72s/it]
38%|###7 | 3/8 [00:17<00:29, 5.98s/it]
50%|##### | 4/8 [00:24<00:25, 6.28s/it]
62%|######2 | 5/8 [00:31<00:19, 6.59s/it]
75%|#######5 | 6/8 [00:39<00:14, 7.04s/it]
88%|########7 | 7/8 [00:48<00:07, 7.55s/it]
100%|##########| 8/8 [00:57<00:00, 8.14s/it]
100%|##########| 8/8 [00:57<00:00, 7.18s/it]
{(1, 2): 0.4797342973574218, (10, 2): 0.47049579850966655, (100, 2): 0.49612963846051455, (1000, 2): 0.6612060813826067, (10000, 2): 0.8796205261312893, (1, 5): 0.47181775759092415, (10, 5): 0.4732894046438794, (100, 5): 0.5149854509394224, (1000, 5): 0.6969026986133698, (10000, 5): 0.8513474370911395, (1, 10): 0.47033357116727087, (10, 10): 0.4721873368613484, (100, 10): 0.511473745800736, (1000, 10): 0.6712626862068822, (10000, 10): 0.8176465855016496, (1, 15): 0.4698205472865529, (10, 15): 0.4639644814668912, (100, 15): 0.5137198248183148, (1000, 15): 0.6700404267711422, (10000, 15): 0.8032539834158782, (1, 20): 0.4763801009988098, (10, 20): 0.47083447577219606, (100, 20): 0.5222021660472781, (1000, 20): 0.655810132576266, (10000, 20): 0.7756895099956939, (1, 30): 0.4727421602667013, (10, 30): 0.48001813793521286, (100, 30): 0.522948605017639, (1000, 30): 0.630522533929567, (10000, 30): 0.7400039747423744, (1, 40): 0.4750104498191635, (10, 40): 0.48023209895808194, (100, 40): 0.5386999036873503, (1000, 40): 0.6360562553863544, (10000, 40): 0.7526225445842833, (1, 50): 0.49382857269923747, (10, 50): 0.480849479800001, (100, 50): 0.537547199304846, (1000, 50): 0.6213147038977004, (10000, 50): 0.7514933133057422}
Graph.
plot_metric(bench_dt, ylabel="classes", transpose=True, shrink=0.75,
title="scikit-learn vs mlprodict (DecisionTreeClassifier) \n"
"< 1 means mlprodict is faster\n no parallelisation")
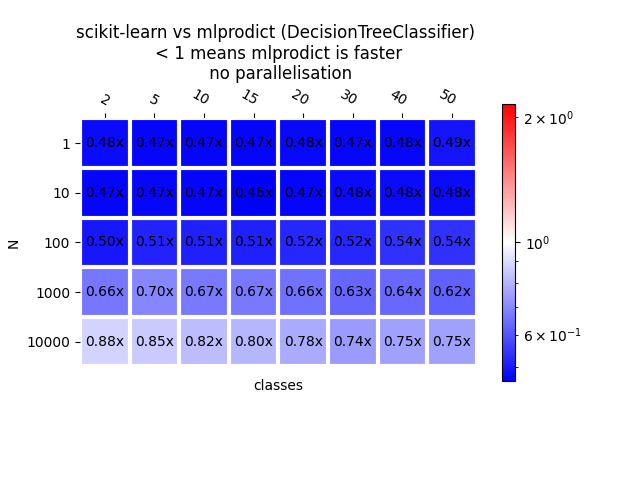
Out:
<AxesSubplot:title={'center':'scikit-learn vs mlprodict (DecisionTreeClassifier) \n< 1 means mlprodict is faster\n no parallelisation'}, xlabel='classes', ylabel='N'>
Multi-class LogisticRegression#
ModelToTest = LogisticRegression
C = [2, 5, 10, 15, 20]
N = [1, 10, 100, 1000, 10000]
models = {}
for cl in tqdm(C):
ntest = 10000
X, y = make_classification(
n_samples=10000 + ntest, n_features=10, n_informative=6,
n_classes=cl, random_state=11)
X_train, X_test, y_train, y_test = (
X[:-ntest], X[-ntest:], y[:-ntest], y[-ntest:])
model = ModelToTest().fit(X_train, y_train)
X32 = X_test.astype(numpy.float32)
monnx = to_onnx(model, X32[:1])
oinf = OnnxInference(monnx)
models[cl] = dict(model=model, X_test=X_test,
X32=X32, monnx=monnx, oinf=oinf)
bench_lr = tree_benchmark(lambda cl: models[cl]['X32'],
lambda cl: models[cl]['model'].predict_proba,
lambda cl: (
lambda x, c=cl: trees[c]['oinf'].run({'X': x})),
C, N)
bench_lr
Out:
0%| | 0/5 [00:00<?, ?it/s]
20%|## | 1/5 [00:00<00:01, 2.86it/s]
40%|#### | 2/5 [00:01<00:01, 1.57it/s]
60%|###### | 3/5 [00:02<00:01, 1.35it/s]
80%|######## | 4/5 [00:03<00:01, 1.02s/it]
100%|##########| 5/5 [00:05<00:00, 1.26s/it]
100%|##########| 5/5 [00:05<00:00, 1.04s/it]
0%| | 0/5 [00:00<?, ?it/s]
20%|## | 1/5 [00:05<00:23, 5.95s/it]
40%|#### | 2/5 [00:14<00:22, 7.46s/it]
60%|###### | 3/5 [00:24<00:17, 8.69s/it]
80%|######## | 4/5 [00:36<00:09, 9.83s/it]
100%|##########| 5/5 [00:49<00:00, 11.11s/it]
100%|##########| 5/5 [00:49<00:00, 9.92s/it]
{(1, 2): 0.3849319770884322, (10, 2): 0.40000987494648116, (100, 2): 0.43899778090911046, (1000, 2): 0.6474817832338519, (10000, 2): 1.0765846661654122, (1, 5): 0.3312081925564331, (10, 5): 0.3198861175396883, (100, 5): 0.3173678802718868, (1000, 5): 0.30756030549891666, (10000, 5): 0.30548624900466753, (1, 10): 0.3275660638395715, (10, 10): 0.3162654061095607, (100, 10): 0.29416226629923015, (1000, 10): 0.24986670203387762, (10000, 10): 0.23724662930264473, (1, 15): 0.3260647910819572, (10, 15): 0.3078937501594963, (100, 15): 0.28067428532487915, (1000, 15): 0.22220749365205916, (10000, 15): 0.21927784613582538, (1, 20): 0.3304397188627888, (10, 20): 0.3045965221312652, (100, 20): 0.2589541420752453, (1000, 20): 0.19489912740528315, (10000, 20): 0.18057346738584967}
Graph.
plot_metric(bench_lr, ylabel="classes",
title="scikit-learn vs mlprodict (LogisticRegression) \n"
"< 1 means mlprodict is faster\n no parallelisation")
Out:
<AxesSubplot:title={'center':'scikit-learn vs mlprodict (LogisticRegression) \n< 1 means mlprodict is faster\n no parallelisation'}, xlabel='N', ylabel='classes'>
Decision Tree and number of features#
ModelToTest = DecisionTreeClassifier
NF = [2, 10, 20, 40, 50, 70, 100, 200, 500, 1000]
N = [1, 10, 100, 1000, 10000, 50000]
trees_nf = {}
for nf in tqdm(NF):
ntest = 10000
X, y = make_classification(
n_samples=10000 + ntest, n_features=nf, n_informative=nf // 2 + 1,
n_redundant=0, n_repeated=0,
n_classes=2, random_state=11)
X_train, X_test, y_train, y_test = (
X[:-ntest], X[-ntest:], y[:-ntest], y[-ntest:])
dt = ModelToTest(max_depth=7).fit(X_train, y_train)
X32 = X_test.astype(numpy.float32)
monnx = to_onnx(dt, X32[:1])
oinf = OnnxInference(monnx)
oinf.sequence_[0].ops_.rt_.omp_N_ = 1000000
trees_nf[nf] = dict(model=dt, X_test=X_test,
X32=X32, monnx=monnx, oinf=oinf)
bench_dt_nf = tree_benchmark(
lambda nf: trees_nf[nf]['X32'],
lambda nf: trees_nf[nf]['model'].predict_proba,
lambda nf: (lambda x, c=nf: trees_nf[c]['oinf'].run({'X': x})), NF, N)
bench_dt_nf
Out:
0%| | 0/10 [00:00<?, ?it/s]
10%|# | 1/10 [00:00<00:01, 7.73it/s]
20%|## | 2/10 [00:00<00:01, 4.07it/s]
30%|### | 3/10 [00:01<00:02, 2.52it/s]
40%|#### | 4/10 [00:02<00:04, 1.50it/s]
50%|##### | 5/10 [00:03<00:04, 1.10it/s]
60%|###### | 6/10 [00:05<00:04, 1.22s/it]
70%|####### | 7/10 [00:07<00:05, 1.68s/it]
80%|######## | 8/10 [00:13<00:05, 2.80s/it]
90%|######### | 9/10 [00:26<00:06, 6.09s/it]
100%|##########| 10/10 [00:54<00:00, 12.89s/it]
100%|##########| 10/10 [00:54<00:00, 5.45s/it]
0%| | 0/10 [00:00<?, ?it/s]
10%|# | 1/10 [00:09<01:25, 9.47s/it]
20%|## | 2/10 [00:18<01:15, 9.50s/it]
30%|### | 3/10 [00:28<01:07, 9.64s/it]
40%|#### | 4/10 [00:38<00:58, 9.77s/it]
50%|##### | 5/10 [00:48<00:49, 9.90s/it]
60%|###### | 6/10 [00:59<00:40, 10.02s/it]
70%|####### | 7/10 [01:09<00:30, 10.26s/it]
80%|######## | 8/10 [01:22<00:22, 11.10s/it]
90%|######### | 9/10 [01:40<00:13, 13.20s/it]
100%|##########| 10/10 [02:05<00:00, 16.75s/it]
100%|##########| 10/10 [02:05<00:00, 12.53s/it]
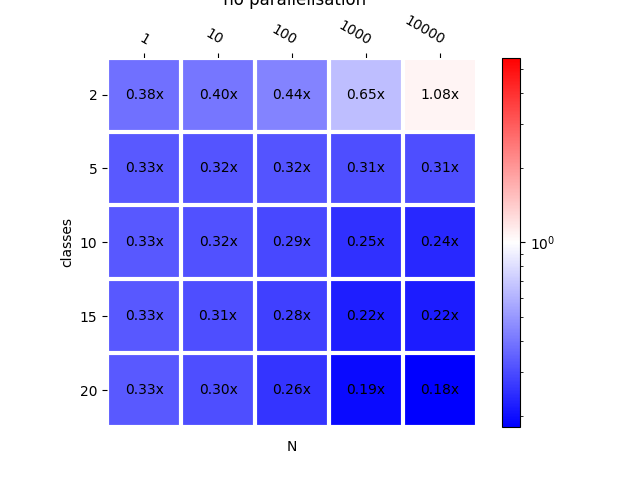
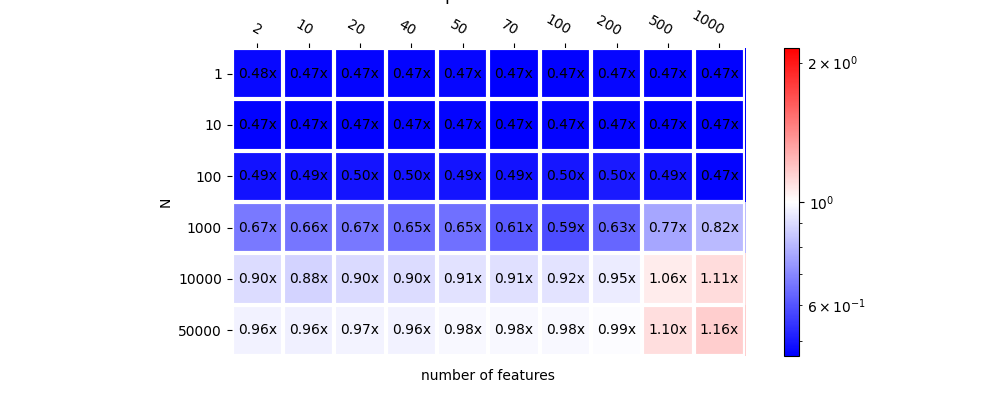
{(1, 2): 0.4776332354278456, (10, 2): 0.4692195482661804, (100, 2): 0.49362311452626034, (1000, 2): 0.6729299555356348, (10000, 2): 0.9008069903707812, (50000, 2): 0.9640361596292094, (1, 10): 0.4731625499035755, (10, 10): 0.4701336040440532, (100, 10): 0.49326926942596233, (1000, 10): 0.6642829779256914, (10000, 10): 0.8805757475377772, (50000, 10): 0.9555824669691629, (1, 20): 0.470749869976751, (10, 20): 0.4694689450911203, (100, 20): 0.49654244410721976, (1000, 20): 0.6693912442043274, (10000, 20): 0.8960895847292957, (50000, 20): 0.9683079072843285, (1, 40): 0.4727913763163058, (10, 40): 0.4714507865555438, (100, 40): 0.49513587047524377, (1000, 40): 0.6488184994810332, (10000, 40): 0.8997938154239181, (50000, 40): 0.9627073651244736, (1, 50): 0.4745428864139398, (10, 50): 0.47241674682669704, (100, 50): 0.4943855596826769, (1000, 50): 0.6531426512411326, (10000, 50): 0.9146066210668232, (50000, 50): 0.9774591868678737, (1, 70): 0.46770308500954727, (10, 70): 0.46504726148050135, (100, 70): 0.49208565441665586, (1000, 70): 0.6093315570263641, (10000, 70): 0.9123305069459965, (50000, 70): 0.9772175620711291, (1, 100): 0.47050733635602043, (10, 100): 0.47104984137624273, (100, 100): 0.49744894928230776, (1000, 100): 0.5851790598235195, (10000, 100): 0.9241194391666269, (50000, 100): 0.9811391312700085, (1, 200): 0.47400925296614826, (10, 200): 0.4730930699964868, (100, 200): 0.5044502419971014, (1000, 200): 0.6336783573561434, (10000, 200): 0.9452813676052982, (50000, 200): 0.9908880754435826, (1, 500): 0.46998171724778653, (10, 500): 0.46685124096078334, (100, 500): 0.4935649625882642, (1000, 500): 0.7666350918734185, (10000, 500): 1.0583588012354055, (50000, 500): 1.1012157646066973, (1, 1000): 0.4685314547758537, (10, 1000): 0.46659779513157285, (100, 1000): 0.47082223754292635, (1000, 1000): 0.8156968221318556, (10000, 1000): 1.1081539869632016, (50000, 1000): 1.1551583974971333}
Graph.
plot_metric(
bench_dt_nf, ylabel="number of features", transpose=True, figsize=(10, 4),
title="scikit-learn vs mlprodict (DecisionTreeClassifier) \n"
"< 1 means mlprodict is faster\n no parallelisation")
Out:
<AxesSubplot:title={'center':'scikit-learn vs mlprodict (DecisionTreeClassifier) \n< 1 means mlprodict is faster\n no parallelisation'}, xlabel='number of features', ylabel='N'>
Total running time of the script: ( 26 minutes 50.880 seconds)