Note
Click here to download the full example code
Benchmark Random Forests, Tree Ensemble, Multi-Classification#
The script compares different implementations for the operator TreeEnsembleRegressor for a multi-regression. It replicates the benchmark Benchmark Random Forests, Tree Ensemble, (AoS and SoA) for multi-classification.
Import#
import warnings
from time import perf_counter as time
from multiprocessing import cpu_count
import numpy
from numpy.random import rand
from numpy.testing import assert_almost_equal
import pandas
import matplotlib.pyplot as plt
from sklearn import config_context
from sklearn.ensemble import RandomForestClassifier
from sklearn.utils._testing import ignore_warnings
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
from onnxruntime import InferenceSession
from mlprodict.onnxrt import OnnxInference
Available optimisation on this machine.
from mlprodict.testing.experimental_c_impl.experimental_c import code_optimisation
print(code_optimisation())
Out:
AVX-omp=8
Versions#
def version():
from datetime import datetime
import sklearn
import numpy
import onnx
import onnxruntime
import skl2onnx
import mlprodict
df = pandas.DataFrame([
{"name": "date", "version": str(datetime.now())},
{"name": "numpy", "version": numpy.__version__},
{"name": "scikit-learn", "version": sklearn.__version__},
{"name": "onnx", "version": onnx.__version__},
{"name": "onnxruntime", "version": onnxruntime.__version__},
{"name": "skl2onnx", "version": skl2onnx.__version__},
{"name": "mlprodict", "version": mlprodict.__version__},
])
return df
version()
Implementations to benchmark#
def fcts_model(X, y, max_depth, n_estimators, n_jobs):
"RandomForestClassifier."
rf = RandomForestClassifier(max_depth=max_depth, n_estimators=n_estimators,
n_jobs=n_jobs)
rf.fit(X, y)
initial_types = [('X', FloatTensorType([None, X.shape[1]]))]
onx = convert_sklearn(rf, initial_types=initial_types,
options={id(rf): {'zipmap': False}})
sess = InferenceSession(onx.SerializeToString())
outputs = [o.name for o in sess.get_outputs()]
oinf = OnnxInference(onx, runtime="python")
oinf.sequence_[0].ops_._init(numpy.float32, 1)
name = outputs[1]
oinf2 = OnnxInference(onx, runtime="python")
oinf2.sequence_[0].ops_._init(numpy.float32, 2)
oinf3 = OnnxInference(onx, runtime="python")
oinf3.sequence_[0].ops_._init(numpy.float32, 3)
def predict_skl_predict(X, model=rf):
return rf.predict_proba(X)
def predict_onnxrt_predict(X, sess=sess):
return sess.run(outputs[:1], {'X': X})[0]
def predict_onnx_inference(X, oinf=oinf):
return oinf.run({'X': X})[name]
def predict_onnx_inference2(X, oinf2=oinf2):
return oinf2.run({'X': X})[name]
def predict_onnx_inference3(X, oinf3=oinf3):
return oinf3.run({'X': X})[name]
return {'predict': (
predict_skl_predict, predict_onnxrt_predict,
predict_onnx_inference, predict_onnx_inference2,
predict_onnx_inference3)}
Benchmarks#
def allow_configuration(**kwargs):
return True
def bench(n_obs, n_features, max_depths, n_estimatorss, n_jobss,
methods, repeat=10, verbose=False):
res = []
for nfeat in n_features:
ntrain = 50000
X_train = numpy.empty((ntrain, nfeat)).astype(numpy.float32)
X_train[:, :] = rand(ntrain, nfeat)[:, :]
eps = rand(ntrain) - 0.5
y_train_f = X_train.sum(axis=1) + eps
y_train = (y_train_f > 12).astype(numpy.int64)
y_train[y_train_f > 15] = 2
y_train[y_train_f < 10] = 3
for n_jobs in n_jobss:
for max_depth in max_depths:
for n_estimators in n_estimatorss:
fcts = fcts_model(X_train, y_train,
max_depth, n_estimators, n_jobs)
for n in n_obs:
for method in methods:
fct1, fct2, fct3, fct4, fct5 = fcts[method]
if not allow_configuration(
n=n, nfeat=nfeat, max_depth=max_depth,
n_estimator=n_estimators, n_jobs=n_jobs,
method=method):
continue
obs = dict(n_obs=n, nfeat=nfeat,
max_depth=max_depth,
n_estimators=n_estimators,
method=method,
n_jobs=n_jobs)
# creates different inputs to avoid caching
Xs = []
for r in range(repeat):
x = numpy.empty((n, nfeat))
x[:, :] = rand(n, nfeat)[:, :]
Xs.append(x.astype(numpy.float32))
# measures the baseline
with config_context(assume_finite=True):
st = time()
repeated = 0
for X in Xs:
p1 = fct1(X)
repeated += 1
if time() - st >= 1:
break # stops if longer than a second
end = time()
obs["time_skl"] = (end - st) / repeated
# measures the new implementation
st = time()
r2 = 0
for X in Xs:
p2 = fct2(X)
r2 += 1
if r2 >= repeated:
break
end = time()
obs["time_ort"] = (end - st) / r2
# measures the other new implementation
st = time()
r2 = 0
for X in Xs:
p2 = fct3(X)
r2 += 1
if r2 >= repeated:
break
end = time()
obs["time_mlprodict"] = (end - st) / r2
# measures the other new implementation 2
st = time()
r2 = 0
for X in Xs:
p2 = fct4(X)
r2 += 1
if r2 >= repeated:
break
end = time()
obs["time_mlprodict2"] = (end - st) / r2
# measures the other new implementation 3
st = time()
r2 = 0
for X in Xs:
p2 = fct5(X)
r2 += 1
if r2 >= repeated:
break
end = time()
obs["time_mlprodict3"] = (end - st) / r2
# final
res.append(obs)
if verbose and (len(res) % 1 == 0 or n >= 10000):
print("bench", len(res), ":", obs)
# checks that both produce the same outputs
if n <= 10000:
if len(p1.shape) == 1 and len(p2.shape) == 2:
p2 = p2.ravel()
try:
assert_almost_equal(
p1.ravel(), p2.ravel(), decimal=5)
except AssertionError as e:
warnings.warn(str(e))
return res
Graphs#
def plot_rf_models(dfr):
def autolabel(ax, rects):
for rect in rects:
height = rect.get_height()
ax.annotate('%1.1fx' % height,
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom',
fontsize=8)
engines = [_.split('_')[-1] for _ in dfr.columns if _.startswith("time_")]
engines = [_ for _ in engines if _ != 'skl']
for engine in engines:
dfr["speedup_%s" % engine] = dfr["time_skl"] / dfr["time_%s" % engine]
print(dfr.tail().T)
ncols = 4
fig, axs = plt.subplots(len(engines), ncols, figsize=(
14, 4 * len(engines)), sharey=True)
row = 0
for row, engine in enumerate(engines):
pos = 0
name = "RandomForestClassifier - %s" % engine
for max_depth in sorted(set(dfr.max_depth)):
for nf in sorted(set(dfr.nfeat)):
for est in sorted(set(dfr.n_estimators)):
for n_jobs in sorted(set(dfr.n_jobs)):
sub = dfr[(dfr.max_depth == max_depth) &
(dfr.nfeat == nf) &
(dfr.n_estimators == est) &
(dfr.n_jobs == n_jobs)]
ax = axs[row, pos]
labels = sub.n_obs
means = sub["speedup_%s" % engine]
x = numpy.arange(len(labels))
width = 0.90
rects1 = ax.bar(x, means, width, label='Speedup')
if pos == 0:
ax.set_yscale('log')
ax.set_ylim([0.1, max(dfr["speedup_%s" % engine])])
if pos == 0:
ax.set_ylabel('Speedup')
ax.set_title(
'%s\ndepth %d - %d features\n %d estimators '
'%d jobs' % (name, max_depth, nf, est, n_jobs))
if row == len(engines) - 1:
ax.set_xlabel('batch size')
ax.set_xticks(x)
ax.set_xticklabels(labels)
autolabel(ax, rects1)
for tick in ax.xaxis.get_major_ticks():
tick.label.set_fontsize(8)
for tick in ax.yaxis.get_major_ticks():
tick.label.set_fontsize(8)
pos += 1
fig.tight_layout()
return fig, ax
Run benchs#
@ignore_warnings(category=FutureWarning)
def run_bench(repeat=100, verbose=False):
n_obs = [1, 10, 100, 1000, 10000]
methods = ['predict']
n_features = [30]
max_depths = [6, 8, 10, 12]
n_estimatorss = [100]
n_jobss = [cpu_count()]
start = time()
results = bench(n_obs, n_features, max_depths, n_estimatorss, n_jobss,
methods, repeat=repeat, verbose=verbose)
end = time()
results_df = pandas.DataFrame(results)
print("Total time = %0.3f sec cpu=%d\n" % (end - start, cpu_count()))
# plot the results
return results_df
name = "plot_random_forest_cls_multi"
df = run_bench(verbose=True)
df.to_csv("%s.csv" % name, index=False)
df.to_excel("%s.xlsx" % name, index=False)
fig, ax = plot_rf_models(df)
fig.savefig("%s.png" % name)
plt.show()
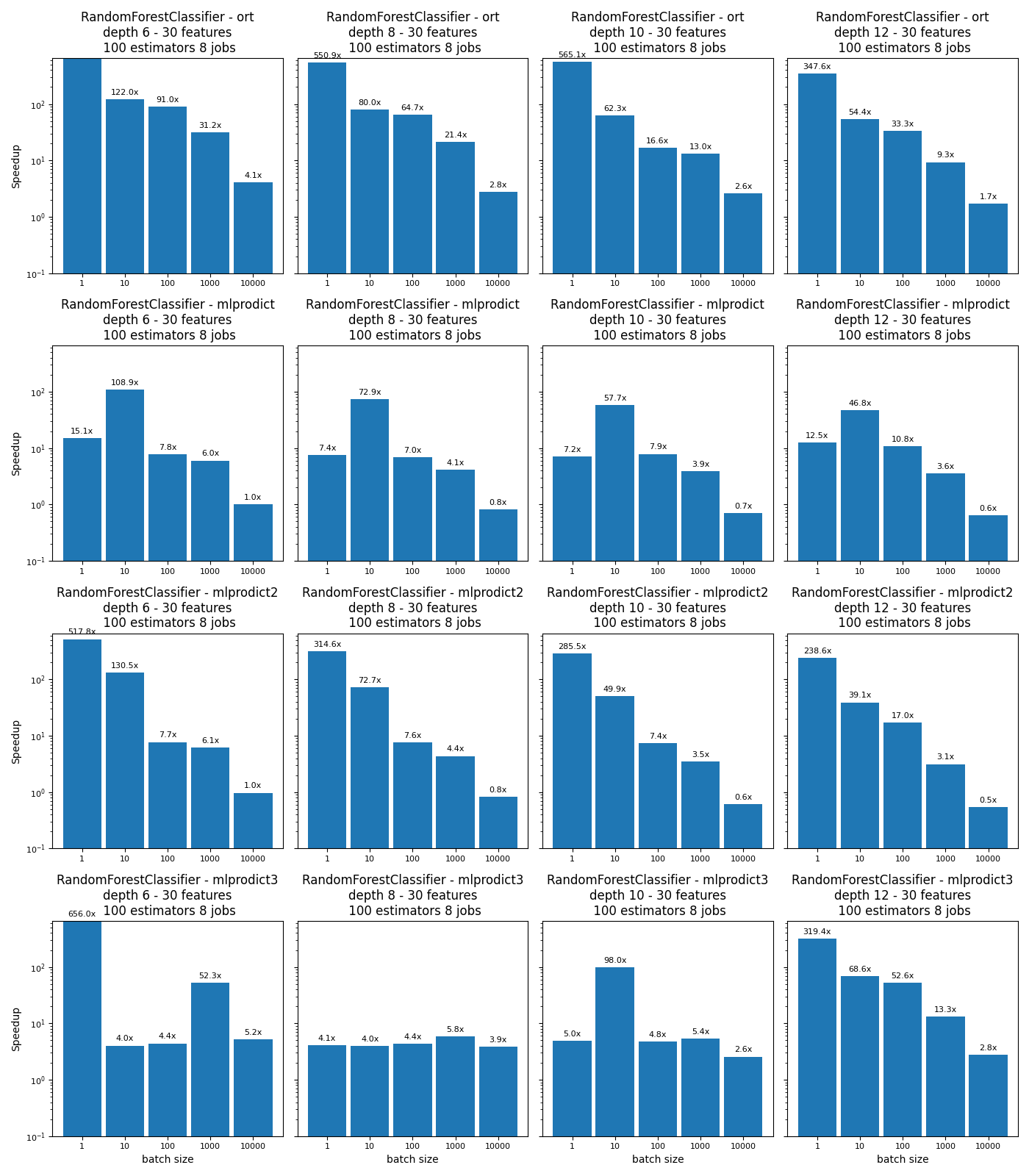
Out:
bench 1 : {'n_obs': 1, 'nfeat': 30, 'max_depth': 6, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.06301232788246125, 'time_ort': 9.430840145796537e-05, 'time_mlprodict': 0.0041689348872751, 'time_mlprodict2': 0.00012168125249445438, 'time_mlprodict3': 9.605276864022017e-05}
bench 2 : {'n_obs': 10, 'nfeat': 30, 'max_depth': 6, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.06402749288827181, 'time_ort': 0.0005246552173048258, 'time_mlprodict': 0.0005881194956600666, 'time_mlprodict2': 0.0004906742833554745, 'time_mlprodict3': 0.015879117185249925}
bench 3 : {'n_obs': 100, 'nfeat': 30, 'max_depth': 6, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.07118329579631487, 'time_ort': 0.0007824125389258067, 'time_mlprodict': 0.009117890149354935, 'time_mlprodict2': 0.009192521994312605, 'time_mlprodict3': 0.016162547717491784}
bench 4 : {'n_obs': 1000, 'nfeat': 30, 'max_depth': 6, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.11302937670714325, 'time_ort': 0.003624949190351698, 'time_mlprodict': 0.018798700637287565, 'time_mlprodict2': 0.018542282076345548, 'time_mlprodict3': 0.0021596153577168784}
bench 5 : {'n_obs': 10000, 'nfeat': 30, 'max_depth': 6, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.15031504418168748, 'time_ort': 0.03693076143307345, 'time_mlprodict': 0.1482563984713384, 'time_mlprodict2': 0.1545610156442438, 'time_mlprodict3': 0.028733927756547928}
bench 6 : {'n_obs': 1, 'nfeat': 30, 'max_depth': 8, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.06307540962006897, 'time_ort': 0.00011450063902884722, 'time_mlprodict': 0.00846771220676601, 'time_mlprodict2': 0.0002004941925406456, 'time_mlprodict3': 0.015280743944458663}
bench 7 : {'n_obs': 10, 'nfeat': 30, 'max_depth': 8, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.06575985439121723, 'time_ort': 0.0008223134791478515, 'time_mlprodict': 0.0009022456360980868, 'time_mlprodict2': 0.0009046612540259957, 'time_mlprodict3': 0.016432303935289383}
bench 8 : {'n_obs': 100, 'nfeat': 30, 'max_depth': 8, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.07240439126534122, 'time_ort': 0.0011188011350376265, 'time_mlprodict': 0.010403630722846304, 'time_mlprodict2': 0.009556019412619727, 'time_mlprodict3': 0.016588997361915454}
bench 9 : {'n_obs': 1000, 'nfeat': 30, 'max_depth': 8, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.11310077913933331, 'time_ort': 0.005292251913083924, 'time_mlprodict': 0.027471332914299436, 'time_mlprodict2': 0.02593311895098951, 'time_mlprodict3': 0.019396711140871048}
bench 10 : {'n_obs': 10000, 'nfeat': 30, 'max_depth': 8, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.15770563163927623, 'time_ort': 0.056597521528601646, 'time_mlprodict': 0.19299355282315186, 'time_mlprodict2': 0.19317455376897538, 'time_mlprodict3': 0.04051996394991875}
bench 11 : {'n_obs': 1, 'nfeat': 30, 'max_depth': 10, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.06237287260591984, 'time_ort': 0.00011037531144478741, 'time_mlprodict': 0.008704744936788784, 'time_mlprodict2': 0.00021843195838086745, 'time_mlprodict3': 0.012580938308554538}
bench 12 : {'n_obs': 10, 'nfeat': 30, 'max_depth': 10, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.0664558595744893, 'time_ort': 0.0010665851878002286, 'time_mlprodict': 0.001152340555563569, 'time_mlprodict2': 0.001330904895439744, 'time_mlprodict3': 0.0006782098207622766}
bench 13 : {'n_obs': 100, 'nfeat': 30, 'max_depth': 10, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.08218540007678363, 'time_ort': 0.0049645384916892415, 'time_mlprodict': 0.01044499773818713, 'time_mlprodict2': 0.011110744797266446, 'time_mlprodict3': 0.017126041679428175}
bench 14 : {'n_obs': 1000, 'nfeat': 30, 'max_depth': 10, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.11646963862909211, 'time_ort': 0.008937697236736616, 'time_mlprodict': 0.02963022618658013, 'time_mlprodict2': 0.03328991702033414, 'time_mlprodict3': 0.021709621366527345}
bench 15 : {'n_obs': 10000, 'nfeat': 30, 'max_depth': 10, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.16213940722601755, 'time_ort': 0.06246421805449894, 'time_mlprodict': 0.23094350339046546, 'time_mlprodict2': 0.2635724137404135, 'time_mlprodict3': 0.06295230851641723}
bench 16 : {'n_obs': 1, 'nfeat': 30, 'max_depth': 12, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.06109827340525739, 'time_ort': 0.00017577519311624414, 'time_mlprodict': 0.004885989405653056, 'time_mlprodict2': 0.000256109654026873, 'time_mlprodict3': 0.00019128160441623013}
bench 17 : {'n_obs': 10, 'nfeat': 30, 'max_depth': 12, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.06698329610129197, 'time_ort': 0.0012309531370798747, 'time_mlprodict': 0.0014300792167584102, 'time_mlprodict2': 0.0017126756409804025, 'time_mlprodict3': 0.0009768559286991755}
bench 18 : {'n_obs': 100, 'nfeat': 30, 'max_depth': 12, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.08195933384390977, 'time_ort': 0.0024615599272342827, 'time_mlprodict': 0.007573268447930996, 'time_mlprodict2': 0.004832952928084593, 'time_mlprodict3': 0.0015574838393009626}
bench 19 : {'n_obs': 1000, 'nfeat': 30, 'max_depth': 12, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.11595478426251146, 'time_ort': 0.012409557070997026, 'time_mlprodict': 0.03250903160207801, 'time_mlprodict2': 0.03690557719932662, 'time_mlprodict3': 0.008750858199265268}
bench 20 : {'n_obs': 10000, 'nfeat': 30, 'max_depth': 12, 'n_estimators': 100, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.16230671560125692, 'time_ort': 0.09396831850920405, 'time_mlprodict': 0.2551133512918438, 'time_mlprodict2': 0.3002052655709641, 'time_mlprodict3': 0.05824805609881878}
Total time = 291.966 sec cpu=8
15 16 17 18 19
n_obs 1 10 100 1000 10000
nfeat 30 30 30 30 30
max_depth 12 12 12 12 12
n_estimators 100 100 100 100 100
method predict predict predict predict predict
n_jobs 8 8 8 8 8
time_skl 0.061098 0.066983 0.081959 0.115955 0.162307
time_ort 0.000176 0.001231 0.002462 0.01241 0.093968
time_mlprodict 0.004886 0.00143 0.007573 0.032509 0.255113
time_mlprodict2 0.000256 0.001713 0.004833 0.036906 0.300205
time_mlprodict3 0.000191 0.000977 0.001557 0.008751 0.058248
speedup_ort 347.593266 54.415797 33.295689 9.343991 1.727249
speedup_mlprodict 12.50479 46.838871 10.822188 3.566848 0.636214
speedup_mlprodict2 238.562945 39.110322 16.958438 3.141931 0.540652
speedup_mlprodict3 319.415312 68.570292 52.622911 13.250676 2.786474
Total running time of the script: ( 5 minutes 8.492 seconds)