Note
Click here to download the full example code
Benchmark operator Slice¶
This short code compares the execution of the operator Slice on CPU and GPU in three configurations.
A simple example¶
import numpy
from numpy.testing import assert_almost_equal
from pandas import DataFrame, pivot_table
from onnxruntime import InferenceSession, get_device
from onnxruntime.capi._pybind_state import ( # pylint: disable=E0611
OrtValue as C_OrtValue)
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx.algebra.onnx_ops import OnnxSlice, OnnxAdd, OnnxMul
from cpyquickhelper.numbers.speed_measure import measure_time
from mlprodict.testing.experimental_c_impl.experimental_c import code_optimisation
from mlprodict.onnxrt import OnnxInference
from mlprodict.plotting.plotting_onnx import plot_onnx
from onnxcustom.utils.onnxruntime_helper import get_ort_device
from tqdm import tqdm
print([code_optimisation(), get_device()])
Out:
['AVX-omp=8', 'CPU']
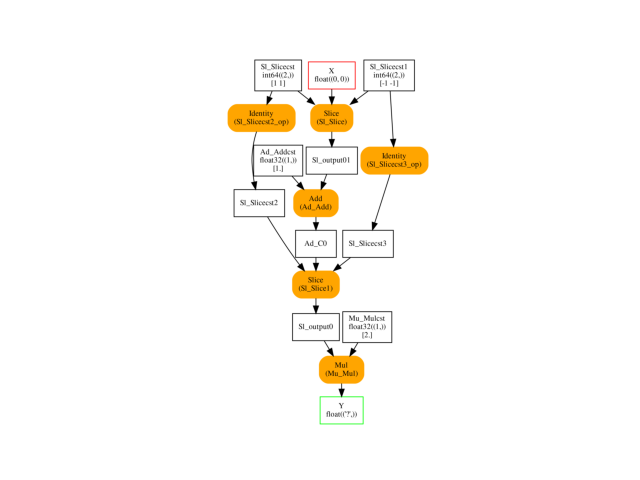
The graph to compare.
def build_ort_op(op_version=14, save=None, slices=None): # opset=13, 14, ...
if slices is None:
starts = numpy.array([1, 1], dtype=numpy.int64)
ends = numpy.array([-1, -1], dtype=numpy.int64)
axes = None
else:
starts, ends = slices
if starts[0] is None:
indexes = [i for i in range(len(starts)) if starts[i] is not None]
starts = numpy.array(
[n for n in starts if n is not None], dtype=numpy.int64)
ends = numpy.array(
[n for n in ends if n is not None], dtype=numpy.int64)
axes = numpy.array(indexes, dtype=numpy.int64)
else:
starts = numpy.array(starts, dtype=numpy.int64)
ends = numpy.array(ends, dtype=numpy.int64)
axes = None
if axes is None:
node1 = OnnxSlice('X', starts, ends, op_version=op_version)
else:
node1 = OnnxSlice('X', starts, ends, axes, op_version=op_version)
node2 = OnnxAdd(node1, numpy.array([1], dtype=numpy.float32),
op_version=op_version)
if axes is None:
node3 = OnnxSlice(node2, starts, ends, op_version=op_version)
else:
node3 = OnnxSlice(node2, starts, ends, axes, op_version=op_version)
node4 = OnnxMul(node3, numpy.array([2], dtype=numpy.float32),
op_version=op_version, output_names=['Y'])
onx = node4.to_onnx(inputs=[('X', FloatTensorType([None, None]))],
target_opset=op_version)
return onx
onx = build_ort_op()
plot_onnx(onx)
Out:
<AxesSubplot:>
Execution on CPU¶
x = numpy.random.rand(50, 50).astype(numpy.float32)
oinf = OnnxInference(onx)
oinf.run({'X': x}, verbose=1, fLOG=print)
Out:
+ki='Sl_Slicecst': (2,) (dtype=int64 min=1 max=1)
+ki='Sl_Slicecst1': (2,) (dtype=int64 min=-1 max=-1)
+ki='Ad_Addcst': (1,) (dtype=float32 min=1.0 max=1.0)
+ki='Mu_Mulcst': (1,) (dtype=float32 min=2.0 max=2.0)
-- OnnxInference: run 6 nodes
Onnx-Identity(Sl_Slicecst) -> Sl_Slicecst2 (name='Sl_Slicecst2_op')
+kr='Sl_Slicecst2': (2,) (dtype=int64 min=1 max=1)
Onnx-Identity(Sl_Slicecst1) -> Sl_Slicecst3 (name='Sl_Slicecst3_op')
+kr='Sl_Slicecst3': (2,) (dtype=int64 min=-1 max=-1)
Onnx-Slice(X, Sl_Slicecst, Sl_Slicecst1) -> Sl_output01 (name='Sl_Slice')
+kr='Sl_output01': (48, 48) (dtype=float32 min=8.141066791722551e-05 max=0.9998125433921814)
Onnx-Add(Sl_output01, Ad_Addcst) -> Ad_C0 (name='Ad_Add')
+kr='Ad_C0': (48, 48) (dtype=float32 min=1.0000814199447632 max=1.9998126029968262)
Onnx-Slice(Ad_C0, Sl_Slicecst2, Sl_Slicecst3) -> Sl_output0 (name='Sl_Slice1')
+kr='Sl_output0': (46, 46) (dtype=float32 min=1.0000814199447632 max=1.9998126029968262)
Onnx-Mul(Sl_output0, Mu_Mulcst) -> Y (name='Mu_Mul')
+kr='Y': (46, 46) (dtype=float32 min=2.0001628398895264 max=3.9996252059936523)
{'Y': array([[2.202823 , 2.3310156, 3.7436275, ..., 3.395742 , 3.6053634,
3.893557 ],
[2.0253925, 3.8714616, 2.7886271, ..., 2.9062228, 2.9643648,
2.6978688],
[2.7763417, 3.8809776, 3.2185361, ..., 2.3637347, 3.59551 ,
2.441475 ],
...,
[2.415699 , 3.4867158, 3.6288283, ..., 3.279631 , 2.7204676,
3.8106637],
[3.6561089, 3.1871939, 2.5588193, ..., 2.2869947, 2.3464262,
2.1570392],
[3.0212526, 3.8279028, 2.8945808, ..., 3.6432106, 3.2940612,
2.3520088]], dtype=float32)}
With onnxruntime.
sess = InferenceSession(onx.SerializeToString(),
providers=["CPUExecutionProvider"])
y_cpu = sess.run(None, {'X': x})[0]
Execution on GPU¶
If available…
if get_device().upper() == 'GPU':
dev = get_ort_device('cuda:0')
try:
gx = C_OrtValue.ortvalue_from_numpy(x, dev)
cuda = True
except RuntimeError as e:
print(e)
cuda = False
else:
cuda = False
if cuda:
sessg = InferenceSession(onx.SerializeToString(),
providers=["CUDAExecutionProvider"])
io_binding = sessg.io_binding()._iobinding
io_binding.bind_input(
'X', dev, numpy.float32, gx.shape(), gx.data_ptr())
io_binding.bind_output('Y', dev)
sessg._sess.run_with_iobinding(io_binding, None)
y_gpu = io_binding.copy_outputs_to_cpu()[0]
assert_almost_equal(y_cpu, y_gpu)
Benchmark¶
data = []
shapes = ([(n, n) for n in [10, 100, 1000]] +
[(n, 100) for n in [10, 100, 1000, 10000]] +
[(100, n) for n in [10, 100, 1000, 10000]])
slices = [([1, 1], [-1, -1]), ([1], [-1]), ([None, 1], [None, -1])]
shape_slices = [(sh, sl) for sh in shapes for sl in slices]
for shape, slices in tqdm(shape_slices):
onx = build_ort_op(slices=slices)
x = numpy.random.rand(*shape).astype(numpy.float32)
number = 100
if x.size >= 100000:
number = 10
sess = InferenceSession(
onx.SerializeToString(),
providers=["CPUExecutionProvider"])
sess.run(None, {'X': x})
obs = dict(
shape=str(shape).replace(
" ", ""), slice=str(slices).replace(
" ", ""))
r = measure_time(lambda: sess.run(None, {'X': x}),
number=number, div_by_number=True,
context={})
obs.update(r)
obs['provider'] = 'CPU'
data.append(obs)
if cuda:
def sess_run(sess, io_binding, x, dev):
io_binding.bind_input(
'X', dev, numpy.float32, gx.shape(), gx.data_ptr())
io_binding.bind_output('Y', dev)
sess._sess.run_with_iobinding(io_binding)
io_binding = sess.io_binding()._iobinding
sess = InferenceSession(
onx.SerializeToString(),
providers=["CUDAExecutionProvider"])
dev = get_ort_device('cuda:0')
gx = C_OrtValue.ortvalue_from_numpy(x, dev)
sess_run(sess, io_binding, gx, dev)
obs = dict(
shape=str(shape).replace(
" ", ""), slice=str(slices).replace(
" ", ""))
r = measure_time(
lambda: sess_run(sess, io_binding, io_binding, gx, dev),
number=number,
div_by_number=True,
context={
'sess': sess, 'gx': gx, 'io_binding': io_binding,
'dev': dev, 'sess_run': sess_run})
obs.update(r)
obs['provider'] = 'GPU'
data.append(obs)
df = DataFrame(data)
print(df)
Out:
0%| | 0/33 [00:00<?, ?it/s]
3%|3 | 1/33 [00:00<00:03, 8.32it/s]
6%|6 | 2/33 [00:00<00:03, 8.91it/s]
9%|9 | 3/33 [00:00<00:03, 8.92it/s]
12%|#2 | 4/33 [00:00<00:03, 7.99it/s]
15%|#5 | 5/33 [00:00<00:03, 7.55it/s]
18%|#8 | 6/33 [00:00<00:03, 7.19it/s]
21%|##1 | 7/33 [00:01<00:08, 3.16it/s]
24%|##4 | 8/33 [00:02<00:10, 2.31it/s]
27%|##7 | 9/33 [00:02<00:12, 1.94it/s]
30%|### | 10/33 [00:02<00:08, 2.56it/s]
33%|###3 | 11/33 [00:03<00:06, 3.25it/s]
36%|###6 | 12/33 [00:03<00:05, 4.01it/s]
39%|###9 | 13/33 [00:03<00:04, 4.59it/s]
42%|####2 | 14/33 [00:03<00:03, 5.11it/s]
45%|####5 | 15/33 [00:03<00:03, 5.47it/s]
48%|####8 | 16/33 [00:03<00:02, 6.06it/s]
52%|#####1 | 17/33 [00:03<00:02, 6.58it/s]
55%|#####4 | 18/33 [00:04<00:02, 6.90it/s]
58%|#####7 | 19/33 [00:04<00:04, 3.16it/s]
61%|###### | 20/33 [00:05<00:05, 2.20it/s]
64%|######3 | 21/33 [00:06<00:06, 1.88it/s]
67%|######6 | 22/33 [00:06<00:04, 2.46it/s]
70%|######9 | 23/33 [00:06<00:03, 3.12it/s]
73%|#######2 | 24/33 [00:06<00:02, 3.85it/s]
76%|#######5 | 25/33 [00:06<00:01, 4.44it/s]
79%|#######8 | 26/33 [00:06<00:01, 4.97it/s]
82%|########1 | 27/33 [00:07<00:01, 5.36it/s]
85%|########4 | 28/33 [00:07<00:00, 6.06it/s]
88%|########7 | 29/33 [00:07<00:00, 6.67it/s]
91%|######### | 30/33 [00:07<00:00, 7.05it/s]
94%|#########3| 31/33 [00:08<00:00, 3.34it/s]
97%|#########6| 32/33 [00:08<00:00, 2.43it/s]
100%|##########| 33/33 [00:09<00:00, 2.01it/s]
100%|##########| 33/33 [00:09<00:00, 3.51it/s]
shape slice ... context_size provider
0 (10,10) ([1,1],[-1,-1]) ... 64 CPU
1 (10,10) ([1],[-1]) ... 64 CPU
2 (10,10) ([None,1],[None,-1]) ... 64 CPU
3 (100,100) ([1,1],[-1,-1]) ... 64 CPU
4 (100,100) ([1],[-1]) ... 64 CPU
5 (100,100) ([None,1],[None,-1]) ... 64 CPU
6 (1000,1000) ([1,1],[-1,-1]) ... 64 CPU
7 (1000,1000) ([1],[-1]) ... 64 CPU
8 (1000,1000) ([None,1],[None,-1]) ... 64 CPU
9 (10,100) ([1,1],[-1,-1]) ... 64 CPU
10 (10,100) ([1],[-1]) ... 64 CPU
11 (10,100) ([None,1],[None,-1]) ... 64 CPU
12 (100,100) ([1,1],[-1,-1]) ... 64 CPU
13 (100,100) ([1],[-1]) ... 64 CPU
14 (100,100) ([None,1],[None,-1]) ... 64 CPU
15 (1000,100) ([1,1],[-1,-1]) ... 64 CPU
16 (1000,100) ([1],[-1]) ... 64 CPU
17 (1000,100) ([None,1],[None,-1]) ... 64 CPU
18 (10000,100) ([1,1],[-1,-1]) ... 64 CPU
19 (10000,100) ([1],[-1]) ... 64 CPU
20 (10000,100) ([None,1],[None,-1]) ... 64 CPU
21 (100,10) ([1,1],[-1,-1]) ... 64 CPU
22 (100,10) ([1],[-1]) ... 64 CPU
23 (100,10) ([None,1],[None,-1]) ... 64 CPU
24 (100,100) ([1,1],[-1,-1]) ... 64 CPU
25 (100,100) ([1],[-1]) ... 64 CPU
26 (100,100) ([None,1],[None,-1]) ... 64 CPU
27 (100,1000) ([1,1],[-1,-1]) ... 64 CPU
28 (100,1000) ([1],[-1]) ... 64 CPU
29 (100,1000) ([None,1],[None,-1]) ... 64 CPU
30 (100,10000) ([1,1],[-1,-1]) ... 64 CPU
31 (100,10000) ([1],[-1]) ... 64 CPU
32 (100,10000) ([None,1],[None,-1]) ... 64 CPU
[33 rows x 11 columns]
Better display¶
piv = pivot_table(
df, index=["shape", "slice"], columns="provider", values="average")
if 'GPU' in piv.columns:
piv['ratio'] = piv['GPU'] / piv['CPU']
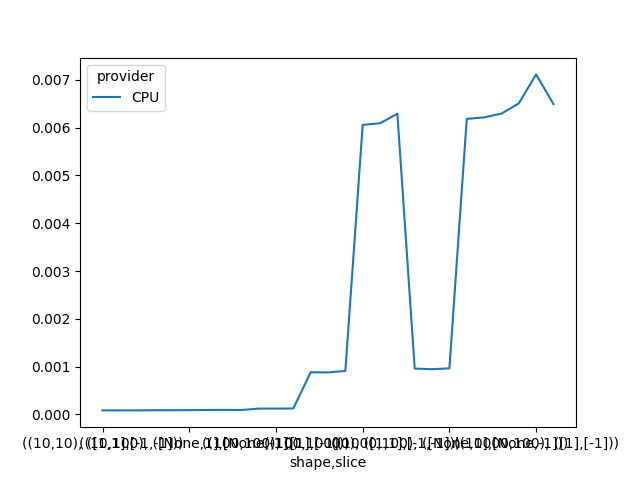
print(piv)
Out:
provider CPU
shape slice
(10,10) ([1,1],[-1,-1]) 0.000084
([1],[-1]) 0.000084
([None,1],[None,-1]) 0.000085
(10,100) ([1,1],[-1,-1]) 0.000088
([1],[-1]) 0.000088
([None,1],[None,-1]) 0.000090
(100,10) ([1,1],[-1,-1]) 0.000093
([1],[-1]) 0.000095
([None,1],[None,-1]) 0.000092
(100,100) ([1,1],[-1,-1]) 0.000122
([1],[-1]) 0.000122
([None,1],[None,-1]) 0.000125
(100,1000) ([1,1],[-1,-1]) 0.000882
([1],[-1]) 0.000878
([None,1],[None,-1]) 0.000910
(100,10000) ([1,1],[-1,-1]) 0.006057
([1],[-1]) 0.006091
([None,1],[None,-1]) 0.006290
(1000,100) ([1,1],[-1,-1]) 0.000959
([1],[-1]) 0.000946
([None,1],[None,-1]) 0.000964
(1000,1000) ([1,1],[-1,-1]) 0.006183
([1],[-1]) 0.006215
([None,1],[None,-1]) 0.006293
(10000,100) ([1,1],[-1,-1]) 0.006508
([1],[-1]) 0.007114
([None,1],[None,-1]) 0.006491
Graphs.
piv.plot()
Out:
<AxesSubplot:xlabel='shape,slice'>
Total running time of the script: ( 0 minutes 11.672 seconds)