Note
Click here to download the full example code
Train a linear regression with onnxruntime-training on GPU in details¶
This example follows the same steps introduced in example Train a linear regression with onnxruntime-training in details but on GPU. This example works on CPU and GPU but automatically chooses GPU if it is available. The main change in this example is the parameter device which indicates where the computation takes place, on CPU or GPU.
A simple linear regression with scikit-learn¶
This code begins like example Train a linear regression with onnxruntime-training in details. It creates a graph to train a linear regression initialized with random coefficients.
from pprint import pprint
import numpy
from pandas import DataFrame
from onnx import helper, numpy_helper, TensorProto
from onnxruntime import (
__version__ as ort_version, get_device,
TrainingParameters, SessionOptions, TrainingSession)
from onnxruntime.capi._pybind_state import ( # pylint: disable=E0611
OrtValue as C_OrtValue)
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from onnxcustom.plotting.plotting_onnx import plot_onnxs
from onnxcustom.utils.onnxruntime_helper import get_ort_device
from tqdm import tqdm
X, y = make_regression(n_features=2, bias=2)
X = X.astype(numpy.float32)
y = y.astype(numpy.float32)
X_train, X_test, y_train, y_test = train_test_split(X, y)
def onnx_linear_regression_training(coefs, intercept):
if len(coefs.shape) == 1:
coefs = coefs.reshape((1, -1))
coefs = coefs.T
# input
X = helper.make_tensor_value_info(
'X', TensorProto.FLOAT, [None, coefs.shape[0]])
# expected input
label = helper.make_tensor_value_info(
'label', TensorProto.FLOAT, [None, coefs.shape[1]])
# output
Y = helper.make_tensor_value_info(
'Y', TensorProto.FLOAT, [None, coefs.shape[1]])
# loss
loss = helper.make_tensor_value_info('loss', TensorProto.FLOAT, [])
# inference
node_matmul = helper.make_node('MatMul', ['X', 'coefs'], ['y1'], name='N1')
node_add = helper.make_node('Add', ['y1', 'intercept'], ['Y'], name='N2')
# loss
node_diff = helper.make_node('Sub', ['Y', 'label'], ['diff'], name='L1')
node_square = helper.make_node(
'Mul', ['diff', 'diff'], ['diff2'], name='L2')
node_square_sum = helper.make_node(
'ReduceSum', ['diff2'], ['loss'], name='L3')
# initializer
init_coefs = numpy_helper.from_array(coefs, name="coefs")
init_intercept = numpy_helper.from_array(intercept, name="intercept")
# graph
graph_def = helper.make_graph(
[node_matmul, node_add, node_diff, node_square, node_square_sum],
'lrt', [X, label], [loss, Y], [init_coefs, init_intercept])
model_def = helper.make_model(
graph_def, producer_name='orttrainer', ir_version=7,
producer_version=ort_version,
opset_imports=[helper.make_operatorsetid('', 14)])
return model_def
onx_train = onnx_linear_regression_training(
numpy.random.randn(2).astype(numpy.float32),
numpy.random.randn(1).astype(numpy.float32))
plot_onnxs(onx_train, title="Graph with Loss")
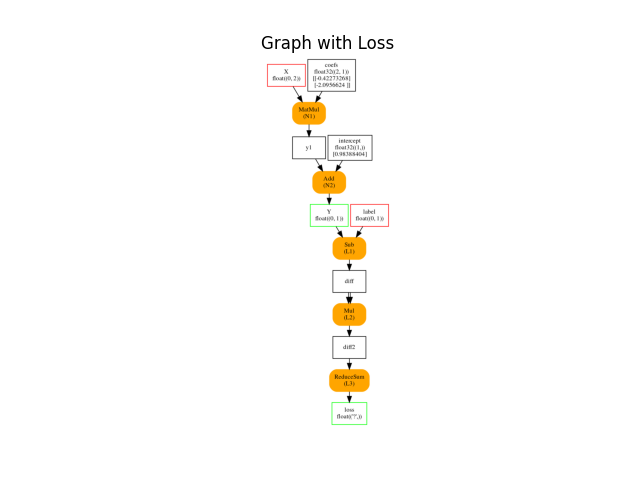
Out:
<AxesSubplot:title={'center':'Graph with Loss'}>
First iterations of training on GPU¶
Prediction needs an instance of class InferenceSession, the training needs an instance of class TrainingSession. Next function creates this one.
device = "cuda" if get_device().upper() == 'GPU' else 'cpu'
print("device=%r get_device()=%r" % (device, get_device()))
Out:
device='cpu' get_device()='CPU'
Function creating the training session.
def create_training_session(
training_onnx, weights_to_train, loss_output_name='loss',
training_optimizer_name='SGDOptimizer', device='cpu'):
"""
Creates an instance of class `TrainingSession`.
:param training_onnx: ONNX graph used to train
:param weights_to_train: names of initializers to be optimized
:param loss_output_name: name of the loss output
:param training_optimizer_name: optimizer name
:param device: `'cpu'` or `'cuda'`
:return: instance of `TrainingSession`
"""
ort_parameters = TrainingParameters()
ort_parameters.loss_output_name = loss_output_name
output_types = {}
for output in training_onnx.graph.output:
output_types[output.name] = output.type.tensor_type
ort_parameters.weights_to_train = set(weights_to_train)
ort_parameters.training_optimizer_name = training_optimizer_name
ort_parameters.optimizer_attributes_map = {
name: {} for name in weights_to_train}
ort_parameters.optimizer_int_attributes_map = {
name: {} for name in weights_to_train}
session_options = SessionOptions()
session_options.use_deterministic_compute = True
if hasattr(device, 'device_type'):
if device.device_type() == device.cpu():
provider = ['CPUExecutionProvider']
elif device.device_type() == device.cuda():
provider = ['CUDAExecutionProvider']
else:
raise ValueError("Unexpected device %r." % device)
else:
if device == 'cpu':
provider = ['CPUExecutionProvider']
elif device.startswith("cuda"):
provider = ['CUDAExecutionProvider']
else:
raise ValueError("Unexpected device %r." % device)
session = TrainingSession(
training_onnx.SerializeToString(), ort_parameters, session_options,
providers=provider)
return session
train_session = create_training_session(
onx_train, ['coefs', 'intercept'], device=device)
print(train_session)
Out:
<onnxruntime.capi.training.training_session.TrainingSession object at 0x7f5cbcee95e0>
The coefficients.
state_tensors = train_session.get_state()
pprint(state_tensors)
Out:
{'coefs': array([[-0.42273268],
[-2.0956624 ]], dtype=float32),
'intercept': array([0.98388404], dtype=float32)}
We can now check the coefficients are updated after one iteration.
dev = get_ort_device(device)
ortx = C_OrtValue.ortvalue_from_numpy(X_train[:1], dev)
orty = C_OrtValue.ortvalue_from_numpy(y_train[:1].reshape((-1, 1)), dev)
ortlr = C_OrtValue.ortvalue_from_numpy(
numpy.array([0.01], dtype=numpy.float32), dev)
bind = train_session.io_binding()._iobinding
bind.bind_ortvalue_input('X', ortx)
bind.bind_ortvalue_input('label', orty)
bind.bind_ortvalue_input('Learning_Rate', ortlr)
bind.bind_output('loss', dev)
train_session._sess.run_with_iobinding(bind, None)
outputs = bind.copy_outputs_to_cpu()
pprint(outputs)
Out:
[array([[126.74382]], dtype=float32)]
We check the coefficients have changed.
state_tensors = train_session.get_state()
pprint(state_tensors)
Out:
{'coefs': array([[-0.2272881],
[-2.018743 ]], dtype=float32),
'intercept': array([1.2090452], dtype=float32)}
Training on GPU¶
We still need to implement a gradient descent. Let’s wrap this into a class similar following scikit-learn’s API. It needs to have an extra parameter device.
class DataLoaderDevice:
"""
Draws consecutive random observations from a dataset
by batch. It iterates over the datasets by drawing
*batch_size* consecutive observations.
:param X: features
:param y: labels
:param batch_size: batch size (consecutive observations)
:param device: `'cpu'`, `'cuda'`, `'cuda:0'`, ...
"""
def __init__(self, X, y, batch_size=20, device='cpu'):
if len(y.shape) == 1:
y = y.reshape((-1, 1))
if X.shape[0] != y.shape[0]:
raise ValueError(
"Shape mismatch X.shape=%r, y.shape=%r." % (X.shape, y.shape))
self.X = numpy.ascontiguousarray(X)
self.y = numpy.ascontiguousarray(y)
self.batch_size = batch_size
self.device = get_ort_device(device)
def __len__(self):
"Returns the number of observations."
return self.X.shape[0]
def __iter__(self):
"""
Iterates over the datasets by drawing
*batch_size* consecutive observations.
"""
N = 0
b = len(self) - self.batch_size
while N < len(self):
i = numpy.random.randint(0, b)
N += self.batch_size
yield (
C_OrtValue.ortvalue_from_numpy(
self.X[i:i + self.batch_size],
self.device),
C_OrtValue.ortvalue_from_numpy(
self.y[i:i + self.batch_size],
self.device))
@property
def data(self):
"Returns a tuple of the datasets."
return self.X, self.y
data_loader = DataLoaderDevice(X_train, y_train, batch_size=2)
for i, batch in enumerate(data_loader):
if i >= 2:
break
print("batch %r: %r" % (i, batch))
Out:
batch 0: (<onnxruntime.capi.onnxruntime_pybind11_state.OrtValue object at 0x7f5d76af6ab0>, <onnxruntime.capi.onnxruntime_pybind11_state.OrtValue object at 0x7f5d76af6870>)
batch 1: (<onnxruntime.capi.onnxruntime_pybind11_state.OrtValue object at 0x7f5d76af6a70>, <onnxruntime.capi.onnxruntime_pybind11_state.OrtValue object at 0x7f5d76af62f0>)
The training algorithm.
class CustomTraining:
"""
Implements a simple :epkg:`Stochastic Gradient Descent`.
:param model_onnx: ONNX graph to train
:param weights_to_train: list of initializers to train
:param loss_output_name: name of output loss
:param max_iter: number of training iterations
:param training_optimizer_name: optimizing algorithm
:param batch_size: batch size (see class *DataLoader*)
:param eta0: initial learning rate for the `'constant'`, `'invscaling'`
or `'adaptive'` schedules.
:param alpha: constant that multiplies the regularization term,
the higher the value, the stronger the regularization.
Also used to compute the learning rate when set to *learning_rate*
is set to `'optimal'`.
:param power_t: exponent for inverse scaling learning rate
:param learning_rate: learning rate schedule:
* `'constant'`: `eta = eta0`
* `'optimal'`: `eta = 1.0 / (alpha * (t + t0))` where *t0* is chosen
by a heuristic proposed by Leon Bottou.
* `'invscaling'`: `eta = eta0 / pow(t, power_t)`
:param device: `'cpu'` or `'cuda'`
:param verbose: use :epkg:`tqdm` to display the training progress
"""
def __init__(self, model_onnx, weights_to_train, loss_output_name='loss',
max_iter=100, training_optimizer_name='SGDOptimizer',
batch_size=10, eta0=0.01, alpha=0.0001, power_t=0.25,
learning_rate='invscaling', device='cpu', verbose=0):
# See https://scikit-learn.org/stable/modules/generated/
# sklearn.linear_model.SGDRegressor.html
self.model_onnx = model_onnx
self.batch_size = batch_size
self.weights_to_train = weights_to_train
self.loss_output_name = loss_output_name
self.training_optimizer_name = training_optimizer_name
self.verbose = verbose
self.max_iter = max_iter
self.eta0 = eta0
self.alpha = alpha
self.power_t = power_t
self.learning_rate = learning_rate.lower()
self.device = get_ort_device(device)
def _init_learning_rate(self):
self.eta0_ = self.eta0
if self.learning_rate == "optimal":
typw = numpy.sqrt(1.0 / numpy.sqrt(self.alpha))
self.eta0_ = typw / max(1.0, (1 + typw) * 2)
self.optimal_init_ = 1.0 / (self.eta0_ * self.alpha)
else:
self.eta0_ = self.eta0
return self.eta0_
def _update_learning_rate(self, t, eta):
if self.learning_rate == "optimal":
eta = 1.0 / (self.alpha * (self.optimal_init_ + t))
elif self.learning_rate == "invscaling":
eta = self.eta0_ / numpy.power(t + 1, self.power_t)
return eta
def fit(self, X, y):
"""
Trains the model.
:param X: features
:param y: expected output
:return: self
"""
self.train_session_ = create_training_session(
self.model_onnx, self.weights_to_train,
loss_output_name=self.loss_output_name,
training_optimizer_name=self.training_optimizer_name,
device=self.device)
data_loader = DataLoaderDevice(
X, y, batch_size=self.batch_size, device=self.device)
lr = self._init_learning_rate()
self.input_names_ = [i.name for i in self.train_session_.get_inputs()]
self.output_names_ = [
o.name for o in self.train_session_.get_outputs()]
self.loss_index_ = self.output_names_.index(self.loss_output_name)
bind = self.train_session_.io_binding()._iobinding
loop = (
tqdm(range(self.max_iter))
if self.verbose else range(self.max_iter))
train_losses = []
for it in loop:
bind_lr = C_OrtValue.ortvalue_from_numpy(
numpy.array([lr], dtype=numpy.float32),
self.device)
loss = self._iteration(data_loader, bind_lr, bind)
lr = self._update_learning_rate(it, lr)
if self.verbose > 1:
loop.set_description("loss=%1.3g lr=%1.3g" % (loss, lr))
train_losses.append(loss)
self.train_losses_ = train_losses
self.trained_coef_ = self.train_session_.get_state()
return self
def _iteration(self, data_loader, learning_rate, bind):
actual_losses = []
for batch_idx, (data, target) in enumerate(data_loader):
bind.bind_ortvalue_input(self.input_names_[0], data)
bind.bind_ortvalue_input(self.input_names_[1], target)
bind.bind_ortvalue_input(self.input_names_[2], learning_rate)
bind.bind_output('loss', self.device)
self.train_session_._sess.run_with_iobinding(bind, None)
outputs = bind.copy_outputs_to_cpu()
actual_losses.append(outputs[self.loss_index_])
return numpy.array(actual_losses).mean()
Let’s now train the model in a very similar way that it would be done with scikit-learn.
trainer = CustomTraining(onx_train, ['coefs', 'intercept'], verbose=1,
max_iter=10, device=device)
trainer.fit(X, y)
print("training losses:", trainer.train_losses_)
df = DataFrame({"iteration": numpy.arange(len(trainer.train_losses_)),
"loss": trainer.train_losses_})
df.set_index('iteration').plot(title="Training loss", logy=True)
Out:
0%| | 0/10 [00:00<?, ?it/s]
100%|##########| 10/10 [00:00<00:00, 319.59it/s]
training losses: [nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]
<AxesSubplot:title={'center':'Training loss'}, xlabel='iteration'>
The final coefficients.
print("onnxruntime", trainer.trained_coef_)
Out:
onnxruntime {'coefs': array([[nan],
[nan]], dtype=float32), 'intercept': array([nan], dtype=float32)}
Total running time of the script: ( 0 minutes 1.936 seconds)