Note
Click here to download the full example code
Add a parser to handle dataframes¶
Change the number of outputs by adding a parser shows how to add a parser to define a converter a model which works differently than standard predictors of scikit-learn. In this case, the input is a dataframe and takes an input per column of the dataframe. One input is impossible because a dataframe may contain different types.
A transformer taking a dataframe as input¶
Some imports…
from pprint import pprint
from pyquickhelper.helpgen.graphviz_helper import plot_graphviz
from mlprodict.onnxrt import OnnxInference
import numpy
from pandas import DataFrame
from onnxruntime import InferenceSession
from sklearn.base import TransformerMixin, BaseEstimator
from sklearn.preprocessing import OrdinalEncoder
from sklearn.tree import DecisionTreeRegressor
from onnxconverter_common.onnx_ops import apply_cast
from skl2onnx.proto import onnx_proto
from skl2onnx import (
update_registered_converter, to_onnx, get_model_alias)
from skl2onnx._parse import _parse_sklearn_simple_model
from skl2onnx.common.data_types import (
Int64TensorType, StringTensorType, FloatTensorType,
_guess_numpy_type)
Later a discretizer is needed. The most efficient way to represent it in ONNX is to use a tree. We could directly convert the discretizer or train a decision tree to predict the bins. The second approach is followed.
class DiscretizeTransformer(TransformerMixin, BaseEstimator):
def __init__(self, thresholds):
BaseEstimator.__init__(self)
TransformerMixin.__init__(self)
self.thresholds = thresholds
def fit(self, X, y=None, sample_weights=None):
# Does nothing.
if len(X.shape) != 2 or X.shape[1]:
raise RuntimeError("The transformer expects only one columns.")
return self
def transform(self, X):
return numpy.digitize(
X, self.thresholds, right=True).reshape((-1, 1))
def astree(self):
"Converters the discretizer as a tree."
X = []
y = []
for i, th in enumerate(self.thresholds):
if i == 0:
th_ = th - (self.thresholds[1] - th) * 0.1
X.append(th_)
y.append(i)
X.append(th)
y.append(i + 1)
else:
th_ = th - (th - self.thresholds[i - 1]) * 0.1
X.append(th_)
y.append(i)
X.append(th)
y.append(i + 1)
tree = DecisionTreeRegressor()
tree.fit(numpy.array(X).reshape((-1, 1)),
numpy.array(y))
# We need to make sure the threshold in three are
# exactly the same.
for i in range(0, len(tree.tree_.threshold)):
if (tree.tree_.children_left[i] > 0 and
tree.tree_.children_right[i] > 0):
# not a leave, let's find the closest threshold
th = tree.tree_.threshold[i]
dist = numpy.abs(self.thresholds - th)
arg = numpy.argmin(dist)
tree.tree_.threshold[i] = self.thresholds[arg]
return tree
X = numpy.array([-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
dtype=numpy.float32).reshape((-1, 1))
bins = numpy.array([0, 2, 4, 9], numpy.float32)
disc = DiscretizeTransformer(bins)
got = disc.transform(X)
print(got.ravel())
Out:
[0 0 1 1 2 2 3 3 3 3 3 4]
Now with the tree.
tree = disc.astree()
pred = tree.predict(X)
print(pred.ravel().astype(numpy.int64))
Out:
[0 0 1 1 2 2 3 3 3 3 3 4]
That works.
class PreprocessDataframeTransformer(TransformerMixin, BaseEstimator):
"""
Converts all columns of a dataframe in integers
than in floats.
"""
def __init__(self):
BaseEstimator.__init__(self)
TransformerMixin.__init__(self)
def fit(self, X, y=None, sample_weights=None):
"Trains the transformer. Creates the member `args_`."
if sample_weights is not None:
raise NotImplementedError(
"sample_weights != None is not implemented.")
if not isinstance(X, DataFrame):
raise TypeError("X must be a dataframe.")
self.args_ = []
for i, (col, dt) in enumerate(zip(X.columns, X.dtypes)):
values = X[col].values
if dt in (numpy.float32, numpy.float64):
qu = numpy.quantile(values, numpy.arange(4) * 0.25)
self.args_.append((i, col, dt, DiscretizeTransformer(qu)))
elif dt == 'category':
oo = OrdinalEncoder(dtype=numpy.int64)
values = values.to_numpy()
oo.fit(values.reshape((-1, 1)))
self.args_.append((i, col, dt, oo))
else:
raise RuntimeError(
"Unable to transform column '{}' type: '{}'.".format(
col, dt))
return self
def transform(self, X):
if not isinstance(X, DataFrame):
raise TypeError("X must be a dataframe.")
outs = []
for i, col, dt, arg in self.args_:
if X.columns[i] != col:
raise RuntimeError(
"Unexpected column name '{}' at position {}.".format(
col, i))
if X.dtypes[i] != dt:
raise RuntimeError(
"Unexpected column type '{}' at position {}.".format(
col, i))
values = X[col].values
if dt in (numpy.float32, numpy.float64):
out = arg.transform(values)
elif dt == 'category':
values = values.to_numpy()
out = arg.transform(values.reshape((-1, 1)))
outs.append(out)
res = numpy.hstack(outs)
return res.astype(numpy.float32)
data = DataFrame([
dict(afloat=0.5, anint=4, astring="A"),
dict(afloat=0.6, anint=5, astring="B"),
dict(afloat=0.7, anint=6, astring="C"),
dict(afloat=0.8, anint=5, astring="D"),
dict(afloat=0.9, anint=4, astring="C"),
dict(afloat=1.0, anint=5, astring="B")])
data['afloat'] = data['afloat'].astype(numpy.float32)
data['anint'] = data['anint'].astype('category')
data['astring'] = data['astring'].astype('category')
dec = PreprocessDataframeTransformer()
dec.fit(data)
pred = dec.transform(data)
print(pred)
Out:
[[0. 0. 0.]
[1. 1. 1.]
[2. 2. 2.]
[3. 1. 3.]
[4. 0. 2.]
[4. 1. 1.]]
Conversion into ONNX¶
The transform has multiple inputs but one outputs. This case is not standard and requires a custom parser. The model ingests different types but returns one output.
def preprocess_dataframe_transformer_parser(
scope, model, inputs, custom_parsers=None):
if len(inputs) != len(model.args_):
raise RuntimeError(
"Converter expects {} inputs but got {}.".format(
len(model.args_), len(inputs)))
transformed_result_names = []
for i, col, dt, arg in model.args_:
if dt in (numpy.float32, numpy.float64):
op = scope.declare_local_operator('CustomDiscretizeTransformer')
op.inputs = [inputs[i]]
op.raw_operator = arg
op_var = scope.declare_local_variable(
'output{}'.format(i), Int64TensorType())
op.outputs.append(op_var)
transformed_result_names.append(op.outputs[0])
elif dt == 'category':
transformed_result_names.append(
_parse_sklearn_simple_model(
scope, arg, [inputs[i]],
custom_parsers=custom_parsers)[0])
# Create a Concat ONNX node
concat_operator = scope.declare_local_operator('SklearnConcat')
concat_operator.inputs = transformed_result_names
union_name = scope.declare_local_variable(
'union', FloatTensorType())
concat_operator.outputs.append(union_name)
return concat_operator.outputs
def preprocess_dataframe_transformer_shape_calculator(operator):
op = operator.raw_operator
input_dim = operator.inputs[0].type.shape[0]
operator.outputs[0].type = FloatTensorType([input_dim, len(op.args_)])
def preprocess_dataframe_transformer_converter(scope, operator, container):
# op = operator.raw_operator
# opv = container.target_opset
# out = operator.outputs
raise NotImplementedError(
"Converter for PreprocessDataframeTransformer is "
"implemented in the parser.")
update_registered_converter(
PreprocessDataframeTransformer,
"CustomPreprocessDataframeTransformer",
preprocess_dataframe_transformer_shape_calculator,
preprocess_dataframe_transformer_converter,
parser=preprocess_dataframe_transformer_parser)
And conversion.
def guess_schema_from_data(data):
res = []
for col, dt in zip(data.columns, data.dtypes):
try:
is_cat = dt == 'category'
except TypeError:
is_cat = False
if is_cat:
if isinstance(dt.categories[0], str):
res.append((col, StringTensorType([None, 1])))
else:
res.append((col, Int64TensorType([None, 1])))
else:
res.append((col, _guess_numpy_type(dt, [None, 1])))
return res
initial_types = guess_schema_from_data(data)
print(initial_types)
try:
onx = to_onnx(dec, initial_types=initial_types,
target_opset={'': 14, 'ai.onnx.ml': 2})
except RuntimeError as e:
print(e)
Out:
[('afloat', FloatTensorType(shape=[None, 1])), ('anint', Int64TensorType(shape=[None, 1])), ('astring', StringTensorType(shape=[None, 1]))]
Unable to find a shape calculator for alias 'CustomDiscretizeTransformer' and type '<class '__main__.DiscretizeTransformer'>'.
It usually means the pipeline being converted contains a
transformer or a predictor with no corresponding converter
implemented in sklearn-onnx. If the converted is implemented
in another library, you need to register
the converted so that it can be used by sklearn-onnx (function
update_registered_converter). If the model is not yet covered
by sklearn-onnx, you may raise an issue to
https://github.com/onnx/sklearn-onnx/issues
to get the converter implemented or even contribute to the
project. If the model is a custom model, a new converter must
be implemented. Examples can be found in the gallery.
The converter for alias DiscretizeTransform is not here. Let’s add it.
def discretizer_transformer_shape_calculator(operator):
operator.outputs[0].type = operator.inputs[0].type.__class__([None, 1])
def discretizer_transformer_converter(scope, operator, container):
op = operator.raw_operator
# We convert the discretizer into a tree.
model = op.astree()
# We add a placeholder to call the converter for
# this model.
alias = get_model_alias(type(model))
op = scope.declare_local_operator(alias)
op.inputs = operator.inputs
op.raw_operator = model
tree_out = scope.declare_local_variable(
'treeout', operator.inputs[0].type.__class__())
op.outputs.append(tree_out)
out_name = operator.outputs[0].full_name
apply_cast(scope, tree_out.full_name, out_name, container,
to=onnx_proto.TensorProto.INT64)
update_registered_converter(
DiscretizeTransformer,
"CustomDiscretizeTransformer",
discretizer_transformer_shape_calculator,
discretizer_transformer_converter)
initial_types = guess_schema_from_data(data)
pprint(initial_types)
onx = to_onnx(dec, initial_types=initial_types,
target_opset={'': 14, 'ai.onnx.ml': 2})
sess = InferenceSession(onx.SerializeToString(),
providers=['CPUExecutionProvider'])
def cvt_col(values):
if hasattr(values, 'to_numpy'):
values = values.to_numpy()
return values.reshape((-1, 1))
inputs = {c: cvt_col(data[c]) for c in data.columns}
exp = dec.transform(data)
results = sess.run(None, inputs)
y = results[0]
def diff(p1, p2):
p1 = p1.ravel()
p2 = p2.ravel()
d = numpy.abs(p2 - p1)
return d.max()
print("expected")
print(exp)
print("ONNX")
print(y)
print("difference", diff(exp, y))
Out:
[('afloat', FloatTensorType(shape=[None, 1])),
('anint', Int64TensorType(shape=[None, 1])),
('astring', StringTensorType(shape=[None, 1]))]
expected
[[0. 0. 0.]
[1. 1. 1.]
[2. 2. 2.]
[3. 1. 3.]
[4. 0. 2.]
[4. 1. 1.]]
ONNX
[[0. 0. 0.]
[1. 1. 1.]
[2. 2. 2.]
[3. 1. 3.]
[4. 0. 2.]
[4. 1. 1.]]
difference 0.0
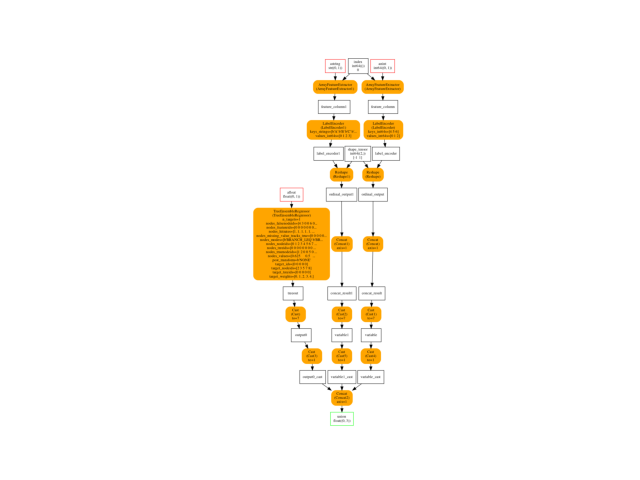
Final graph¶
oinf = OnnxInference(onx, runtime="python_compiled")
ax = plot_graphviz(oinf.to_dot())
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
Total running time of the script: ( 0 minutes 1.462 seconds)