Note
Click here to download the full example code
A new converter with options¶
Options are used to implement different conversion for a same model. The options can be used to replace an operator MatMul by the Gemm operator and compare the processing time for both graph. Let’s see how to retrieve the options within a converter.
Example Implement a new converter implements a converter which uses operator MatMul. Option use_gemm is used to replace MatMul by Gemm.
Custom model¶
from mlprodict.onnxrt import OnnxInference
from pyquickhelper.helpgen.graphviz_helper import plot_graphviz
from pandas import DataFrame
from onnxcustom.utils import measure_time
import numpy
from onnxruntime import InferenceSession
from sklearn.base import TransformerMixin, BaseEstimator
from sklearn.datasets import load_iris
from skl2onnx import update_registered_converter
from skl2onnx.common.data_types import guess_numpy_type
from skl2onnx.algebra.onnx_ops import (
OnnxSub, OnnxMatMul, OnnxGemm)
from skl2onnx import to_onnx
class DecorrelateTransformer(TransformerMixin, BaseEstimator):
"""
Decorrelates correlated gaussian features.
:param alpha: avoids non inversible matrices
by adding *alpha* identity matrix
*Attributes*
* `self.mean_`: average
* `self.coef_`: square root of the coveriance matrix
"""
def __init__(self, alpha=0.):
BaseEstimator.__init__(self)
TransformerMixin.__init__(self)
self.alpha = alpha
def fit(self, X, y=None, sample_weights=None):
if sample_weights is not None:
raise NotImplementedError(
"sample_weights != None is not implemented.")
self.mean_ = numpy.mean(X, axis=0, keepdims=True)
X = X - self.mean_
V = X.T @ X / X.shape[0]
if self.alpha != 0:
V += numpy.identity(V.shape[0]) * self.alpha
L, P = numpy.linalg.eig(V)
Linv = L ** (-0.5)
diag = numpy.diag(Linv)
root = P @ diag @ P.transpose()
self.coef_ = root
return self
def transform(self, X):
return (X - self.mean_) @ self.coef_
data = load_iris()
X = data.data
dec = DecorrelateTransformer()
dec.fit(X)
pred = dec.transform(X[:5])
print(pred)
Out:
[[ 0.0167562 0.52111756 -1.24946737 -0.56194325]
[-0.0727878 -0.80853732 -1.43841018 -0.37441392]
[-0.69971891 -0.09950908 -1.2138161 -0.3499275 ]
[-1.13063404 -0.13540568 -0.79087008 -0.73938966]
[-0.35790036 0.91900236 -1.04034399 -0.6509266 ]]
Conversion into ONNX¶
Let’s try to convert it and see what happens.
def decorrelate_transformer_shape_calculator(operator):
op = operator.raw_operator
input_type = operator.inputs[0].type.__class__
input_dim = operator.inputs[0].type.shape[0]
output_type = input_type([input_dim, op.coef_.shape[1]])
operator.outputs[0].type = output_type
def decorrelate_transformer_converter(scope, operator, container):
op = operator.raw_operator
opv = container.target_opset
out = operator.outputs
X = operator.inputs[0]
dtype = guess_numpy_type(X.type)
options = container.get_options(op, dict(use_gemm=False))
use_gemm = options['use_gemm']
print('conversion: use_gemm=', use_gemm)
if use_gemm:
Y = OnnxGemm(X, op.coef_.astype(dtype),
(- op.mean_ @ op.coef_).astype(dtype),
op_version=opv, alpha=1., beta=1.,
output_names=out[:1])
else:
Y = OnnxMatMul(
OnnxSub(X, op.mean_.astype(dtype), op_version=opv),
op.coef_.astype(dtype),
op_version=opv, output_names=out[:1])
Y.add_to(scope, container)
The registration needs to declare the options supported by the converted.
update_registered_converter(
DecorrelateTransformer, "SklearnDecorrelateTransformer",
decorrelate_transformer_shape_calculator,
decorrelate_transformer_converter,
options={'use_gemm': [True, False]})
onx = to_onnx(dec, X.astype(numpy.float32))
sess = InferenceSession(onx.SerializeToString(),
providers=['CPUExecutionProvider'])
exp = dec.transform(X.astype(numpy.float32))
got = sess.run(None, {'X': X.astype(numpy.float32)})[0]
def diff(p1, p2):
p1 = p1.ravel()
p2 = p2.ravel()
d = numpy.abs(p2 - p1)
return d.max(), (d / numpy.abs(p1)).max()
print(diff(exp, got))
Out:
conversion: use_gemm= False
(1.0531815934911037e-06, 0.0003497831114202993)
We try the non default option, use_gemm: True.
onx2 = to_onnx(dec, X.astype(numpy.float32),
options={'use_gemm': True})
sess2 = InferenceSession(onx2.SerializeToString(),
providers=['CPUExecutionProvider'])
exp = dec.transform(X.astype(numpy.float32))
got2 = sess2.run(None, {'X': X.astype(numpy.float32)})[0]
print(diff(exp, got2))
Out:
conversion: use_gemm= True
(2.0175704165126263e-06, 0.0005483764974245708)
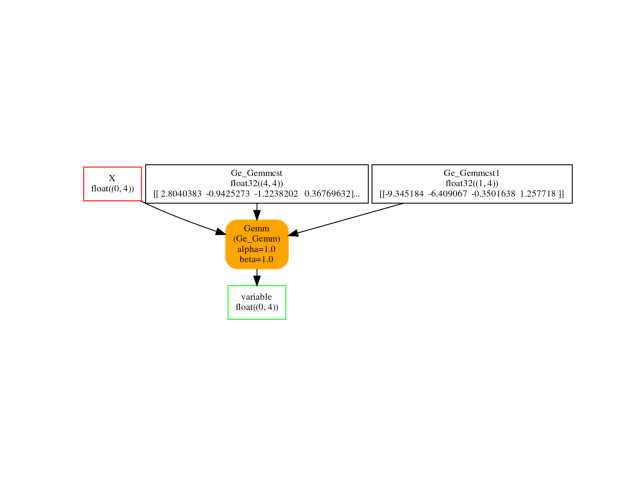
Visually.
oinf = OnnxInference(onx2)
ax = plot_graphviz(oinf.to_dot())
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
Time comparison¶
Let’s compare the two computation.
X32 = X.astype(numpy.float32)
obs = []
context = {'sess': sess, 'X32': X32}
mt = measure_time(
"sess.run(None, {'X': X32})", context, div_by_number=True,
number=100, repeat=1000)
mt['use_gemm'] = False
obs.append(mt)
context = {'sess2': sess2, 'X32': X32}
mt2 = measure_time(
"sess2.run(None, {'X': X32})", context, div_by_number=True,
number=10, repeat=100)
mt2['use_gemm'] = True
obs.append(mt2)
DataFrame(obs).T
Total running time of the script: ( 0 minutes 10.413 seconds)