Note
Click here to download the full example code
Dataframe as an input¶
A pipeline usually ingests data as a matrix. It may be converted in a matrix if all the data share the same type. But data held in a dataframe have usually multiple types, float, integer or string for categories. ONNX also supports that case.
A dataset with categories¶
from mlinsights.plotting import pipeline2dot
import numpy
import pprint
from mlprodict.onnx_conv import guess_schema_from_data
from onnxruntime import InferenceSession
from pyquickhelper.helpgen.graphviz_helper import plot_graphviz
from mlprodict.onnxrt import OnnxInference
from mlprodict.onnx_conv import to_onnx as to_onnx_ext
from skl2onnx import to_onnx
from pandas import DataFrame
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
from sklearn.ensemble import RandomForestClassifier
data = DataFrame([
dict(CAT1='a', CAT2='c', num1=0.5, num2=0.6, y=0),
dict(CAT1='b', CAT2='d', num1=0.4, num2=0.8, y=1),
dict(CAT1='a', CAT2='d', num1=0.5, num2=0.56, y=0),
dict(CAT1='a', CAT2='d', num1=0.55, num2=0.56, y=1),
dict(CAT1='a', CAT2='c', num1=0.35, num2=0.86, y=0),
dict(CAT1='a', CAT2='c', num1=0.5, num2=0.68, y=1),
])
cat_cols = ['CAT1', 'CAT2']
train_data = data.drop('y', axis=1)
categorical_transformer = Pipeline([
('onehot', OneHotEncoder(sparse=False, handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('cat', categorical_transformer, cat_cols)],
remainder='passthrough')
pipe = Pipeline([('preprocess', preprocessor),
('rf', RandomForestClassifier())])
pipe.fit(train_data, data['y'])
Out:
Pipeline(steps=[('preprocess',
ColumnTransformer(remainder='passthrough',
transformers=[('cat',
Pipeline(steps=[('onehot',
OneHotEncoder(handle_unknown='ignore',
sparse=False))]),
['CAT1', 'CAT2'])])),
('rf', RandomForestClassifier())])
Display.
dot = pipeline2dot(pipe, train_data)
ax = plot_graphviz(dot)
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
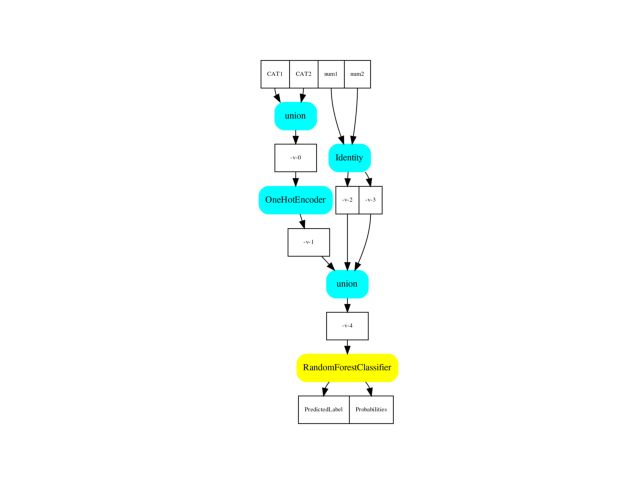
Conversion to ONNX¶
Function to_onnx does not handle dataframes.
try:
onx = to_onnx(pipe, train_data[:1])
except NotImplementedError as e:
print(e)
But it possible to use an extended one.
onx = to_onnx_ext(
pipe, train_data[:1],
options={RandomForestClassifier: {'zipmap': False}})
Graph¶
oinf = OnnxInference(onx)
ax = plot_graphviz(oinf.to_dot())
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
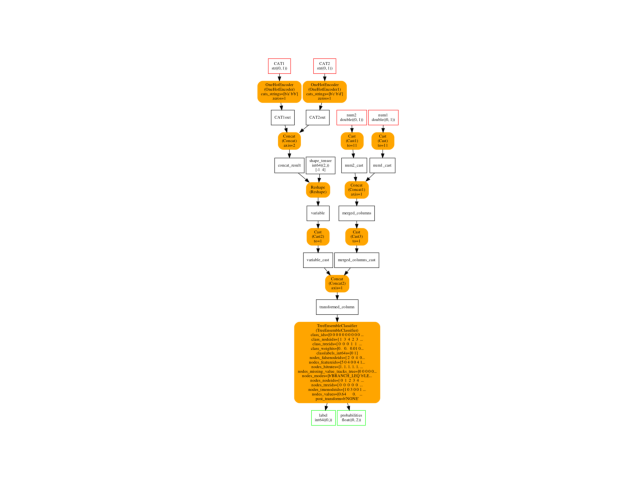
Prediction with ONNX¶
onnxruntime does not support dataframes.
sess = InferenceSession(onx.SerializeToString(),
providers=['CPUExecutionProvider'])
try:
sess.run(None, train_data)
except Exception as e:
print(e)
Out:
run(): incompatible function arguments. The following argument types are supported:
1. (self: onnxruntime.capi.onnxruntime_pybind11_state.InferenceSession, arg0: List[str], arg1: Dict[str, object], arg2: onnxruntime.capi.onnxruntime_pybind11_state.RunOptions) -> List[object]
Invoked with: <onnxruntime.capi.onnxruntime_pybind11_state.InferenceSession object at 0x7f5cde0761b0>, ['label', 'probabilities'], CAT1 CAT2 num1 num2
0 a c 0.50 0.60
1 b d 0.40 0.80
2 a d 0.50 0.56
3 a d 0.55 0.56
4 a c 0.35 0.86
5 a c 0.50 0.68, None
Let’s use a shortcut
oinf = OnnxInference(onx)
got = oinf.run(train_data)
print(pipe.predict(train_data))
print(got['label'])
Out:
[0 1 0 1 0 1]
[0 1 0 1 0 1]
And probilities.
print(pipe.predict_proba(train_data))
print(got['probabilities'])
Out:
[[0.87 0.13]
[0.19 0.81]
[0.76 0.24]
[0.31 0.69]
[0.77 0.23]
[0.33 0.67]]
[[0.87 0.13 ]
[0.19000018 0.8099998 ]
[0.76 0.24 ]
[0.31000012 0.6899999 ]
[0.77 0.22999999]
[0.33000004 0.66999996]]
It looks ok. Let’s dig into the details to directly use onnxruntime.
Unhide conversion logic with a dataframe¶
A dataframe can be seen as a set of columns with different types. That’s what ONNX should see: a list of inputs, the input name is the column name, the input type is the column type.
init = guess_schema_from_data(train_data)
pprint.pprint(init)
Out:
[('CAT1', StringTensorType(shape=[None, 1])),
('CAT2', StringTensorType(shape=[None, 1])),
('num1', DoubleTensorType(shape=[None, 1])),
('num2', DoubleTensorType(shape=[None, 1]))]
Let’s use float instead.
for c in train_data.columns:
if c not in cat_cols:
train_data[c] = train_data[c].astype(numpy.float32)
init = guess_schema_from_data(train_data)
pprint.pprint(init)
Out:
[('CAT1', StringTensorType(shape=[None, 1])),
('CAT2', StringTensorType(shape=[None, 1])),
('num1', FloatTensorType(shape=[None, 1])),
('num2', FloatTensorType(shape=[None, 1]))]
Let’s convert with skl2onnx only.
onx2 = to_onnx(
pipe, initial_types=init,
options={RandomForestClassifier: {'zipmap': False}})
Let’s run it with onnxruntime. We need to convert the dataframe into a dictionary where column names become keys, and column values become values.
inputs = {c: train_data[c].values.reshape((-1, 1))
for c in train_data.columns}
pprint.pprint(inputs)
Out:
{'CAT1': array([['a'],
['b'],
['a'],
['a'],
['a'],
['a']], dtype=object),
'CAT2': array([['c'],
['d'],
['d'],
['d'],
['c'],
['c']], dtype=object),
'num1': array([[0.5 ],
[0.4 ],
[0.5 ],
[0.55],
[0.35],
[0.5 ]], dtype=float32),
'num2': array([[0.6 ],
[0.8 ],
[0.56],
[0.56],
[0.86],
[0.68]], dtype=float32)}
Inference.
sess2 = InferenceSession(onx2.SerializeToString(),
providers=['CPUExecutionProvider'])
got2 = sess2.run(None, inputs)
print(pipe.predict(train_data))
print(got2[0])
Out:
[0 1 0 1 0 1]
[0 1 0 1 0 1]
And probilities.
print(pipe.predict_proba(train_data))
print(got2[1])
Out:
[[0.87 0.13]
[0.19 0.81]
[0.76 0.24]
[0.31 0.69]
[0.77 0.23]
[0.33 0.67]]
[[0.87 0.12999998]
[0.19000047 0.8099995 ]
[0.76 0.24000004]
[0.31000036 0.68999964]
[0.77 0.23000003]
[0.33000034 0.66999966]]
Total running time of the script: ( 0 minutes 4.279 seconds)