Note
Click here to download the full example code
Funny discrepancies¶
Function sigmoid is  .
For small or high value, implementation has to do approximation
and they are not always the same. It may be a tradeoff between
precision and computation time…
It is always a tradeoff.
.
For small or high value, implementation has to do approximation
and they are not always the same. It may be a tradeoff between
precision and computation time…
It is always a tradeoff.
Precision¶
This section compares the precision of a couple of implementations
of the ssigmoid function. The custom implementation is done with
a Taylor expansion of exponential function:
 .
.
import time
import numpy
import pandas
from tqdm import tqdm
from scipy.special import expit
from skl2onnx.algebra.onnx_ops import OnnxSigmoid
from skl2onnx.common.data_types import FloatTensorType
from onnxruntime import InferenceSession
from mlprodict.onnxrt import OnnxInference
from onnxcustom import get_max_opset
import matplotlib.pyplot as plt
one = numpy.array([1], dtype=numpy.float64)
def taylor_approximation_exp(x, degre=50):
y = numpy.zeros(x.shape, dtype=x.dtype)
a = numpy.ones(x.shape, dtype=x.dtype)
for i in range(1, degre + 1):
a *= x / i
y += a
return y
def taylor_sigmoid(x, degre=50):
den = one + taylor_approximation_exp(-x, degre)
return one / (den)
opset = get_max_opset()
N = 300
min_values = [-20 + float(i) * 10 / N for i in range(N)]
data = numpy.array([0], dtype=numpy.float32)
node = OnnxSigmoid('X', op_version=opset, output_names=['Y'])
onx = node.to_onnx({'X': FloatTensorType()},
{'Y': FloatTensorType()},
target_opset=opset)
rts = ['numpy', 'python', 'onnxruntime', 'taylor20', 'taylor40']
oinf = OnnxInference(onx)
sess = InferenceSession(onx.SerializeToString())
graph = []
for mv in tqdm(min_values):
data[0] = mv
for rt in rts:
lab = ""
if rt == 'numpy':
y = expit(data)
elif rt == 'python':
y = oinf.run({'X': data})['Y']
# * 1.2 to avoid curves to be superimposed
y *= 1.2
lab = "x1.2"
elif rt == 'onnxruntime':
y = sess.run(None, {'X': data})[0]
elif rt == 'taylor40':
y = taylor_sigmoid(data, 40)
# * 0.8 to avoid curves to be superimposed
y *= 0.8
lab = "x0.8"
elif rt == 'taylor20':
y = taylor_sigmoid(data, 20)
# * 0.6 to avoid curves to be superimposed
y *= 0.6
lab = "x0.6"
else:
raise AssertionError("Unknown runtime %r." % rt)
value = y[0]
graph.append(dict(rt=rt + lab, x=mv, y=value))
Out:
0%| | 0/300 [00:00<?, ?it/s]
11%|#1 | 33/300 [00:00<00:00, 320.92it/s]
22%|##2 | 66/300 [00:00<00:00, 318.44it/s]
33%|###2 | 98/300 [00:00<00:00, 318.40it/s]
43%|####3 | 130/300 [00:00<00:00, 318.12it/s]
54%|#####4 | 162/300 [00:00<00:00, 318.31it/s]
65%|######4 | 194/300 [00:00<00:00, 318.48it/s]
75%|#######5 | 226/300 [00:00<00:00, 318.56it/s]
86%|########6 | 258/300 [00:00<00:00, 318.52it/s]
97%|#########6| 290/300 [00:00<00:00, 318.56it/s]
100%|##########| 300/300 [00:00<00:00, 318.21it/s]
Graph.
_, ax = plt.subplots(1, 1, figsize=(12, 4))
df = pandas.DataFrame(graph)
piv = df.pivot('x', 'rt', 'y')
print(piv.T.head())
piv.plot(ax=ax, logy=True)
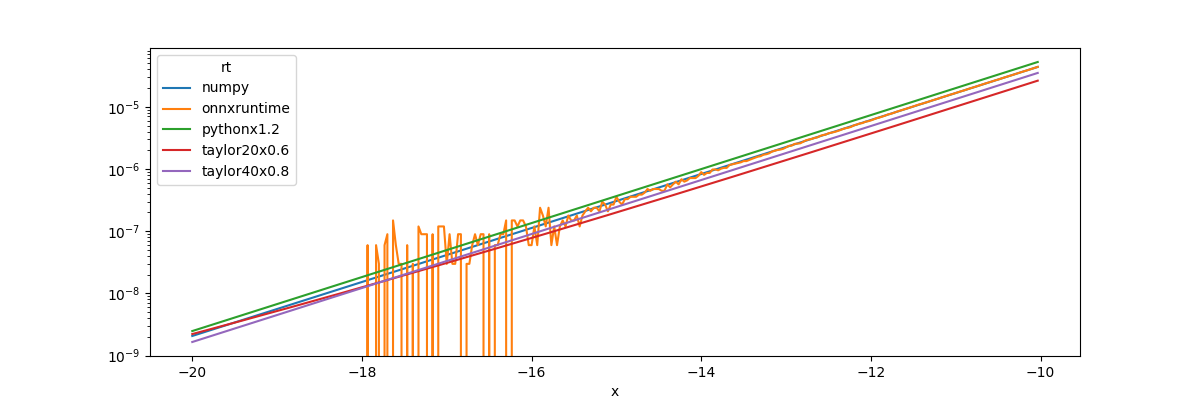
Out:
x -20.000000 -19.966667 ... -10.066667 -10.033333
rt ...
numpy 2.061154e-09 2.131016e-09 ... 0.000042 0.000044
onnxruntime -5.960464e-08 -5.960464e-08 ... 0.000042 0.000044
pythonx1.2 2.473385e-09 2.557219e-09 ... 0.000051 0.000053
taylor20x0.6 2.211963e-09 2.274888e-09 ... 0.000026 0.000026
taylor40x0.8 1.648965e-09 1.704854e-09 ... 0.000034 0.000035
[5 rows x 300 columns]
<AxesSubplot:xlabel='x'>
 . When x is very negative,
. When x is very negative,
 . That explains the graph.
We also see onnxruntime is less precise for these values.
What’s the benefit?
. That explains the graph.
We also see onnxruntime is less precise for these values.
What’s the benefit?
Computation time¶
graph = []
for mv in tqdm(min_values):
data = numpy.array([mv] * 10000, dtype=numpy.float32)
for rt in rts:
begin = time.perf_counter()
if rt == 'numpy':
y = expit(data)
elif rt == 'python':
y = oinf.run({'X': data})['Y']
elif rt == 'onnxruntime':
y = sess.run(None, {'X': data})[0]
elif rt == 'taylor40':
y = taylor_sigmoid(data, 40)
elif rt == 'taylor20':
y = taylor_sigmoid(data, 20)
else:
raise AssertionError("Unknown runtime %r." % rt)
duration = time.perf_counter() - begin
graph.append(dict(rt=rt, x=mv, y=duration))
_, ax = plt.subplots(1, 1, figsize=(12, 4))
df = pandas.DataFrame(graph)
piv = df.pivot('x', 'rt', 'y')
piv.plot(ax=ax, logy=True)
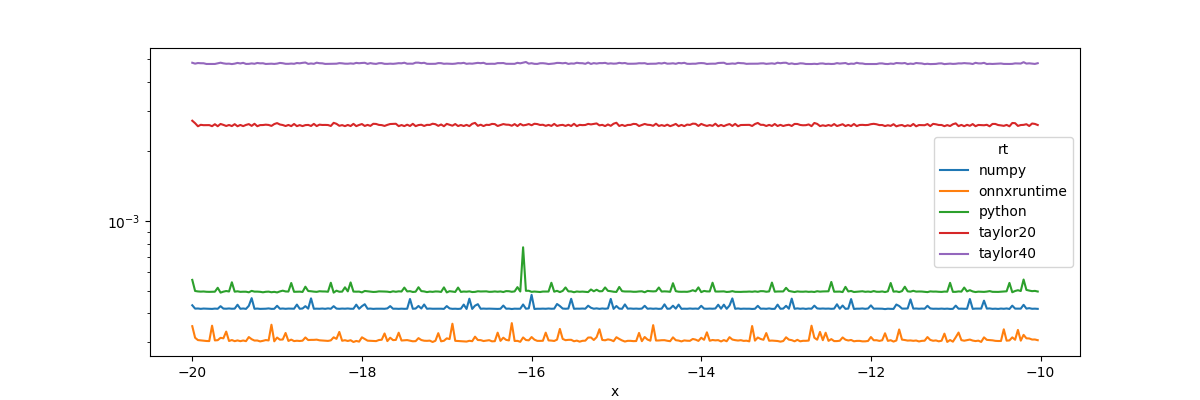
Out:
0%| | 0/300 [00:00<?, ?it/s]
3%|3 | 10/300 [00:00<00:02, 97.91it/s]
7%|6 | 20/300 [00:00<00:02, 97.46it/s]
10%|# | 30/300 [00:00<00:02, 97.31it/s]
13%|#3 | 40/300 [00:00<00:02, 97.25it/s]
17%|#6 | 50/300 [00:00<00:02, 97.20it/s]
20%|## | 60/300 [00:00<00:02, 97.14it/s]
23%|##3 | 70/300 [00:00<00:02, 97.12it/s]
27%|##6 | 80/300 [00:00<00:02, 97.11it/s]
30%|### | 90/300 [00:00<00:02, 97.10it/s]
33%|###3 | 100/300 [00:01<00:02, 97.10it/s]
37%|###6 | 110/300 [00:01<00:01, 97.09it/s]
40%|#### | 120/300 [00:01<00:01, 96.96it/s]
43%|####3 | 130/300 [00:01<00:01, 96.99it/s]
47%|####6 | 140/300 [00:01<00:01, 97.04it/s]
50%|##### | 150/300 [00:01<00:01, 96.96it/s]
53%|#####3 | 160/300 [00:01<00:01, 96.98it/s]
57%|#####6 | 170/300 [00:01<00:01, 97.00it/s]
60%|###### | 180/300 [00:01<00:01, 97.02it/s]
63%|######3 | 190/300 [00:01<00:01, 97.03it/s]
67%|######6 | 200/300 [00:02<00:01, 97.05it/s]
70%|####### | 210/300 [00:02<00:00, 97.06it/s]
73%|#######3 | 220/300 [00:02<00:00, 97.10it/s]
77%|#######6 | 230/300 [00:02<00:00, 97.15it/s]
80%|######## | 240/300 [00:02<00:00, 97.14it/s]
83%|########3 | 250/300 [00:02<00:00, 97.15it/s]
87%|########6 | 260/300 [00:02<00:00, 97.17it/s]
90%|######### | 270/300 [00:02<00:00, 97.17it/s]
93%|#########3| 280/300 [00:02<00:00, 97.18it/s]
97%|#########6| 290/300 [00:02<00:00, 97.19it/s]
100%|##########| 300/300 [00:03<00:00, 97.06it/s]
100%|##########| 300/300 [00:03<00:00, 97.07it/s]
<AxesSubplot:xlabel='x'>
Conclusion¶
The implementation from onnxruntime is faster but
is much less contiguous for extremes. It explains why
probabilities may be much different when an observation
is far from every classification border. In that case,
onnxruntime implementation of the sigmoid function
returns 0 when numpy.sigmoid() returns a smoother value.
Probabilites of logistic regression are obtained after the raw
scores are transformed with the sigmoid function and
normalized. If the raw scores are very negative,
the sum of probabilities becomes null with onnxruntime.
The normalization fails.
# plt.show()
Total running time of the script: ( 0 minutes 6.687 seconds)