Note
Click here to download the full example code
Convert a pipeline with a XGBoost model¶
sklearn-onnx only converts scikit-learn models into ONNX but many libraries implement scikit-learn API so that their models can be included in a scikit-learn pipeline. This example considers a pipeline including a XGBoost model. sklearn-onnx can convert the whole pipeline as long as it knows the converter associated to a XGBClassifier. Let’s see how to do it.
Train a XGBoost classifier¶
from pyquickhelper.helpgen.graphviz_helper import plot_graphviz
from mlprodict.onnxrt import OnnxInference
import numpy
import onnxruntime as rt
from sklearn.datasets import load_iris, load_diabetes, make_classification
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from xgboost import XGBClassifier, XGBRegressor, DMatrix, train as train_xgb
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx import convert_sklearn, to_onnx, update_registered_converter
from skl2onnx.common.shape_calculator import (
calculate_linear_classifier_output_shapes,
calculate_linear_regressor_output_shapes)
from onnxmltools.convert.xgboost.operator_converters.XGBoost import (
convert_xgboost)
from onnxmltools.convert import convert_xgboost as convert_xgboost_booster
data = load_iris()
X = data.data[:, :2]
y = data.target
ind = numpy.arange(X.shape[0])
numpy.random.shuffle(ind)
X = X[ind, :].copy()
y = y[ind].copy()
pipe = Pipeline([('scaler', StandardScaler()),
('xgb', XGBClassifier(n_estimators=3))])
pipe.fit(X, y)
# The conversion fails but it is expected.
try:
convert_sklearn(pipe, 'pipeline_xgboost',
[('input', FloatTensorType([None, 2]))],
target_opset={'': 14, 'ai.onnx.ml': 2})
except Exception as e:
print(e)
# The error message tells no converter was found
# for :epkg:`XGBoost` models. By default, :epkg:`sklearn-onnx`
# only handles models from :epkg:`scikit-learn` but it can
# be extended to every model following :epkg:`scikit-learn`
# API as long as the module knows there exists a converter
# for every model used in a pipeline. That's why
# we need to register a converter.
Out:
/var/lib/jenkins/workspace/onnxcustom/onnxcustom_UT_39_std/_venv/lib/python3.9/site-packages/xgboost/sklearn.py:1224: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
[02:45:18] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
Register the converter for XGBClassifier¶
The converter is implemented in onnxmltools: onnxmltools…XGBoost.py. and the shape calculator: onnxmltools…Classifier.py.
update_registered_converter(
XGBClassifier, 'XGBoostXGBClassifier',
calculate_linear_classifier_output_shapes, convert_xgboost,
options={'nocl': [True, False], 'zipmap': [True, False, 'columns']})
Convert again¶
model_onnx = convert_sklearn(
pipe, 'pipeline_xgboost',
[('input', FloatTensorType([None, 2]))],
target_opset={'': 14, 'ai.onnx.ml': 2})
# And save.
with open("pipeline_xgboost.onnx", "wb") as f:
f.write(model_onnx.SerializeToString())
Compare the predictions¶
Predictions with XGBoost.
print("predict", pipe.predict(X[:5]))
print("predict_proba", pipe.predict_proba(X[:1]))
Out:
predict [1 2 0 2 1]
predict_proba [[0.13844107 0.5810031 0.28055578]]
Predictions with onnxruntime.
sess = rt.InferenceSession("pipeline_xgboost.onnx",
providers=['CPUExecutionProvider'])
pred_onx = sess.run(None, {"input": X[:5].astype(numpy.float32)})
print("predict", pred_onx[0])
print("predict_proba", pred_onx[1][:1])
Out:
predict [1 2 0 2 1]
predict_proba [{0: 0.1384410709142685, 1: 0.5810031294822693, 2: 0.2805558145046234}]
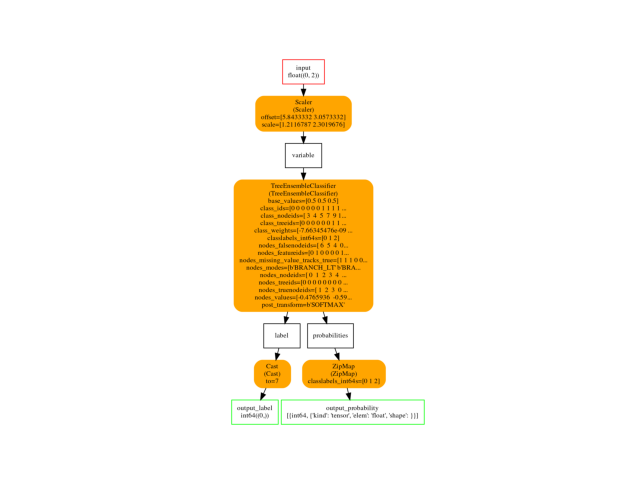
Final graph¶
oinf = OnnxInference(model_onnx)
ax = plot_graphviz(oinf.to_dot())
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
Same example with XGBRegressor¶
update_registered_converter(
XGBRegressor, 'XGBoostXGBRegressor',
calculate_linear_regressor_output_shapes, convert_xgboost)
data = load_diabetes()
x = data.data
y = data.target
X_train, X_test, y_train, _ = train_test_split(x, y, test_size=0.5)
pipe = Pipeline([('scaler', StandardScaler()),
('xgb', XGBRegressor(n_estimators=3))])
pipe.fit(X_train, y_train)
print("predict", pipe.predict(X_test[:5]))
Out:
predict [152.94487 126.392944 152.94487 57.947594 68.90656 ]
ONNX
onx = to_onnx(pipe, X_train.astype(numpy.float32),
target_opset={'': 15, 'ai.onnx.ml': 2})
sess = rt.InferenceSession(onx.SerializeToString(),
providers=['CPUExecutionProvider'])
pred_onx = sess.run(None, {"X": X_test[:5].astype(numpy.float32)})
print("predict", pred_onx[0].ravel())
Out:
predict [152.94487 126.392944 152.94487 57.947594 68.90656 ]
Some discrepencies may appear. In that case, you should read Issues when switching to float.
Same with a Booster¶
A booster cannot be inserted in a pipeline. It requires a different conversion function because it does not follow scikit-learn API.
x, y = make_classification(n_classes=2, n_features=5,
n_samples=100,
random_state=42, n_informative=3)
X_train, X_test, y_train, _ = train_test_split(x, y, test_size=0.5,
random_state=42)
dtrain = DMatrix(X_train, label=y_train)
param = {'objective': 'multi:softmax', 'num_class': 3}
bst = train_xgb(param, dtrain, 10)
initial_type = [('float_input', FloatTensorType([None, X_train.shape[1]]))]
onx = convert_xgboost_booster(bst, "name", initial_types=initial_type)
sess = rt.InferenceSession(onx.SerializeToString(),
providers=['CPUExecutionProvider'])
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
pred_onx = sess.run(
[label_name], {input_name: X_test.astype(numpy.float32)})[0]
print(pred_onx)
Out:
[02:45:20] WARNING: ../src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softmax' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[0 0 1 1 0 1 0 1 0 1 0 0 1 1 1 0 0 1 1 1 1 0 0 1 0 0 0 1 1 1 0 1 1 0 1 1 1
0 1 1 1 0 0 1 1 0 0 0 1 0]
Total running time of the script: ( 0 minutes 2.318 seconds)