Note
Click here to download the full example code
Benchmark inference for a linear regression¶
This short code compares the execution of a couple of runtime for inference including onnxruntime. This benchmark leverages the example Benchmark Linear Regression. This simple model is useful to measure unsignificant cost for large models.
Linear Regression¶
import warnings
from time import perf_counter as time
from multiprocessing import cpu_count
import numpy
from numpy.random import rand
from numpy.testing import assert_almost_equal
import matplotlib.pyplot as plt
import pandas
from onnxruntime import InferenceSession
from onnxruntime.capi._pybind_state import ( # pylint: disable=E0611
SessionIOBinding, OrtDevice as C_OrtDevice)
from sklearn import config_context
from sklearn.linear_model import LinearRegression
from sklearn.utils._testing import ignore_warnings
from skl2onnx import to_onnx
from skl2onnx.common.data_types import FloatTensorType
from mlprodict.onnxrt import OnnxInference
Available optimisation on this machine.
from mlprodict.testing.experimental_c_impl.experimental_c import code_optimisation
print(code_optimisation())
Out:
AVX-omp=8
Implementations to benchmark¶
def fcts_model(X, y, n_jobs):
"LinearRegression."
model = LinearRegression(n_jobs=n_jobs)
model.fit(X, y)
initial_types = [('X', FloatTensorType([None, X.shape[1]]))]
onx = to_onnx(model, initial_types=initial_types,
black_op={'LinearRegressor'})
sess = InferenceSession(onx.SerializeToString(),
providers=['CPUExecutionProvider'])
outputs = [o.name for o in sess.get_outputs()]
oinf = OnnxInference(onx, runtime="python")
bind = SessionIOBinding(sess._sess)
# ort_device = C_OrtDevice.cpu()
ort_device = C_OrtDevice(
C_OrtDevice.cpu(), C_OrtDevice.default_memory(), 0)
def predict_skl_predict(X, model=model):
return model.predict(X)
def predict_onnxrt_predict(X, sess=sess):
return sess.run(outputs[:1], {'X': X})[0]
def predict_onnx_inference(X, oinf=oinf):
return oinf.run({'X': X})["variable"]
def predict_onnxrt_predict_bind(X, sess=sess, bind=bind,
ort_device=ort_device):
if X.__array_interface__['strides'] is not None:
raise RuntimeError("onnxruntime only supports contiguous arrays.")
bind.bind_input('X', ort_device, X.dtype, X.shape,
X.__array_interface__['data'][0])
bind.bind_output('variable', ort_device)
sess._sess.run_with_iobinding(bind, None)
ortvalues = bind.get_outputs()
return ortvalues[0].numpy()
return {'predict': {
'skl': predict_skl_predict,
'ort': predict_onnxrt_predict,
'numpy': predict_onnx_inference,
'ort-bind': predict_onnxrt_predict_bind
}}
Benchmarks¶
def allow_configuration(**kwargs):
return True
def bench(n_obs, n_features, n_jobss,
methods, repeat=10, verbose=False):
res = []
for nfeat in n_features:
ntrain = 50000
X_train = numpy.empty((ntrain, nfeat)).astype(numpy.float32)
X_train[:, :] = rand(ntrain, nfeat)[:, :]
eps = rand(ntrain) - 0.5
y_train = X_train.sum(axis=1) + eps
for n_jobs in n_jobss:
fcts = fcts_model(X_train, y_train, n_jobs)
for n in n_obs:
for method in methods:
if not allow_configuration(n=n, nfeat=nfeat,
n_jobs=n_jobs, method=method):
continue
obs = dict(n_obs=n, nfeat=nfeat, method=method,
n_jobs=n_jobs)
# creates different inputs to avoid caching in any ways
Xs = []
for r in range(repeat):
x = numpy.empty((n, nfeat))
x[:, :] = rand(n, nfeat)[:, :]
Xs.append(x.astype(numpy.float32))
for name, fct in fcts[method].items():
if name == 'skl':
# measures the baseline
with config_context(assume_finite=True):
st = time()
repeated = 0
for X in Xs:
p1 = fct(X)
repeated += 1
if time() - st >= 1:
break # stops if longer than a second
end = time()
obs["time_skl"] = (end - st) / repeated
else:
st = time()
r2 = 0
for X in Xs:
p2 = fct(X)
r2 += 1
if r2 >= repeated:
break
end = time()
obs["time_" + name] = (end - st) / r2
# final
res.append(obs)
if verbose and (len(res) % 1 == 0 or n >= 10000):
print("bench", len(res), ":", obs)
# checks that both produce the same outputs
if n <= 10000:
if len(p1.shape) == 1 and len(p2.shape) == 2:
p2 = p2.ravel()
try:
assert_almost_equal(
p1.ravel(), p2.ravel(), decimal=5)
except AssertionError as e:
warnings.warn(str(e))
return res
Graphs¶
def plot_rf_models(dfr):
def autolabel(ax, rects):
for rect in rects:
height = rect.get_height()
ax.annotate('%1.1fx' % height,
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom',
fontsize=8)
engines = [_.split('_')[-1] for _ in dfr.columns if _.startswith("time_")]
engines = [_ for _ in engines if _ != 'skl']
for engine in engines:
dfr["speedup_%s" % engine] = dfr["time_skl"] / dfr["time_%s" % engine]
print(dfr.tail().T)
ncols = 2
fig, axs = plt.subplots(len(engines), ncols, figsize=(
14, 4 * len(engines)), sharey=True)
row = 0
for row, engine in enumerate(engines):
pos = 0
name = "LinearRegression - %s" % engine
for nf in sorted(set(dfr.nfeat)):
for n_jobs in sorted(set(dfr.n_jobs)):
sub = dfr[(dfr.nfeat == nf) & (dfr.n_jobs == n_jobs)]
ax = axs[row, pos]
labels = sub.n_obs
means = sub["speedup_%s" % engine]
x = numpy.arange(len(labels))
width = 0.90
rects1 = ax.bar(x, means, width, label='Speedup')
if pos == 0:
# ax.set_yscale('log')
ax.set_ylim([0.1, max(dfr["speedup_%s" % engine])])
if pos == 0:
ax.set_ylabel('Speedup')
ax.set_title('%s\n%d features\n%d jobs' % (name, nf, n_jobs))
if row == len(engines) - 1:
ax.set_xlabel('batch size')
ax.set_xticks(x)
ax.set_xticklabels(labels)
autolabel(ax, rects1)
for tick in ax.xaxis.get_major_ticks():
tick.label.set_fontsize(8)
for tick in ax.yaxis.get_major_ticks():
tick.label.set_fontsize(8)
pos += 1
fig.tight_layout()
return fig, ax
Run benchs¶
@ignore_warnings(category=FutureWarning)
def run_bench(repeat=200, verbose=False):
n_obs = [1, 10, 100, 1000, 10000]
methods = ['predict']
n_features = [10, 50]
n_jobss = [cpu_count()]
start = time()
results = bench(n_obs, n_features, n_jobss,
methods, repeat=repeat, verbose=verbose)
end = time()
results_df = pandas.DataFrame(results)
print("Total time = %0.3f sec cpu=%d\n" % (end - start, cpu_count()))
# plot the results
return results_df
name = "plot_linear_regression"
df = run_bench(verbose=True)
# df.to_csv("%s.csv" % name, index=False)
# df.to_excel("%s.xlsx" % name, index=False)
Out:
bench 1 : {'n_obs': 1, 'nfeat': 10, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.0001947406865656376, 'time_ort': 6.786389742046594e-05, 'time_numpy': 0.00021035732235759495, 'time_ort-bind': 0.00011368541978299617}
bench 2 : {'n_obs': 10, 'nfeat': 10, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.00019748535472899676, 'time_ort': 6.2463553622365e-05, 'time_numpy': 0.00021023187786340714, 'time_ort-bind': 0.00010792972985655069}
bench 3 : {'n_obs': 100, 'nfeat': 10, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.0001987773971632123, 'time_ort': 7.037467323243618e-05, 'time_numpy': 0.00021191025152802467, 'time_ort-bind': 0.00011454816907644272}
bench 4 : {'n_obs': 1000, 'nfeat': 10, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.00024468261282891037, 'time_ort': 0.00014540414791554214, 'time_numpy': 0.00023536186665296555, 'time_ort-bind': 0.0001906729768961668}
bench 5 : {'n_obs': 10000, 'nfeat': 10, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.000354369031265378, 'time_ort': 0.0007120366860181093, 'time_numpy': 0.0006251344317570329, 'time_ort-bind': 0.0007483998127281666}
bench 6 : {'n_obs': 1, 'nfeat': 50, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.0003578846482560039, 'time_ort': 6.312559824436903e-05, 'time_numpy': 0.00021172500681132078, 'time_ort-bind': 0.00010883467737585306}
bench 7 : {'n_obs': 10, 'nfeat': 50, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.00019892629235982896, 'time_ort': 6.523582618683576e-05, 'time_numpy': 0.00021182615775614978, 'time_ort-bind': 0.0001107795024290681}
bench 8 : {'n_obs': 100, 'nfeat': 50, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.00020426238421350718, 'time_ort': 9.6201803535223e-05, 'time_numpy': 0.00021750915329903363, 'time_ort-bind': 0.00014088039286434652}
bench 9 : {'n_obs': 1000, 'nfeat': 50, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.0003938441164791584, 'time_ort': 0.0004045076621696353, 'time_numpy': 0.000249230619519949, 'time_ort-bind': 0.0004490335518494248}
bench 10 : {'n_obs': 10000, 'nfeat': 50, 'method': 'predict', 'n_jobs': 8, 'time_skl': 0.0006039750017225742, 'time_ort': 0.001234545223414898, 'time_numpy': 0.0008183290855959058, 'time_ort-bind': 0.0013337316503748298}
Total time = 8.010 sec cpu=8
Results¶
df
Graph¶
fig, ax = plot_rf_models(df)
fig.savefig("%s.png" % name)
# plt.show()
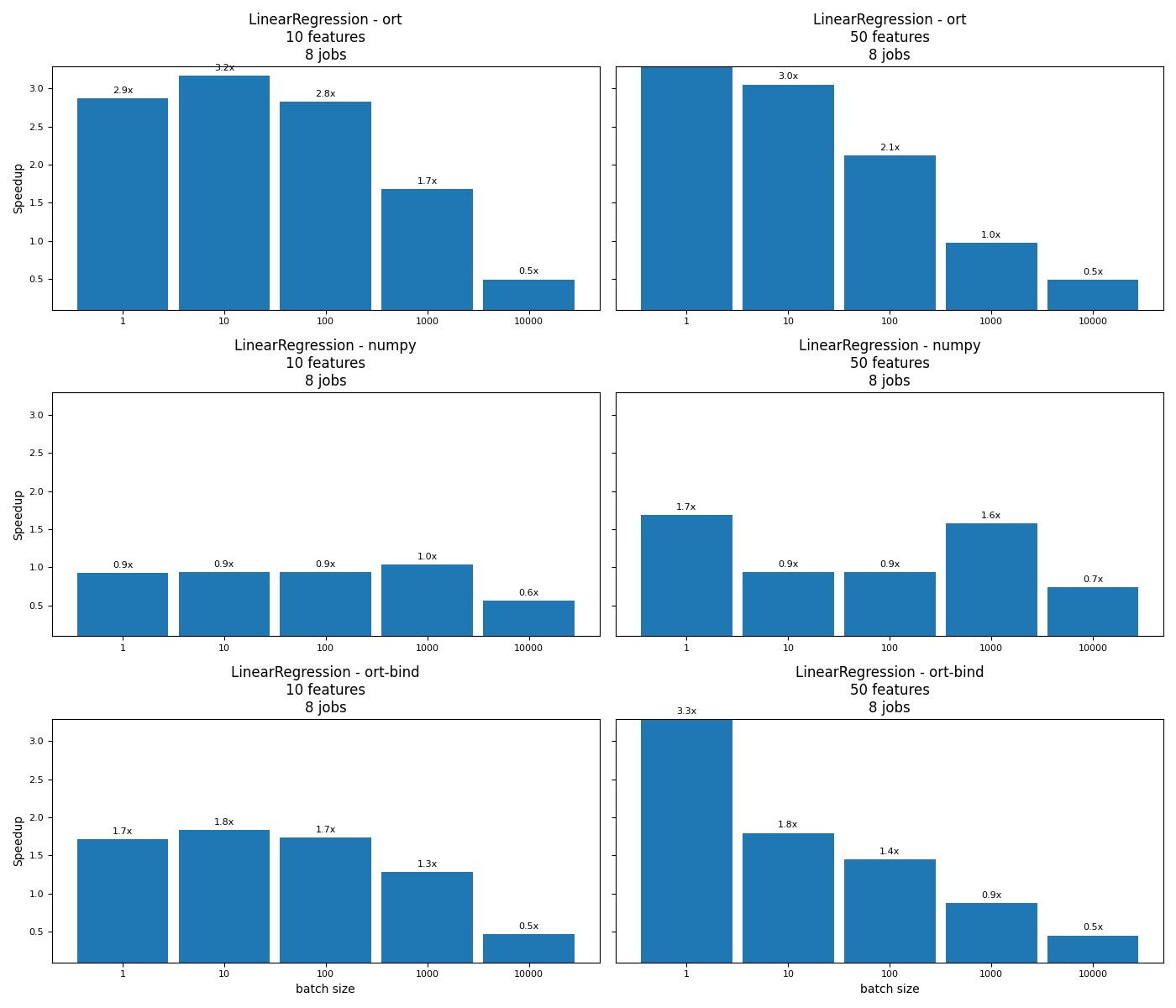
Out:
5 6 7 8 9
n_obs 1 10 100 1000 10000
nfeat 50 50 50 50 50
method predict predict predict predict predict
n_jobs 8 8 8 8 8
time_skl 0.000358 0.000199 0.000204 0.000394 0.000604
time_ort 0.000063 0.000065 0.000096 0.000405 0.001235
time_numpy 0.000212 0.000212 0.000218 0.000249 0.000818
time_ort-bind 0.000109 0.000111 0.000141 0.000449 0.001334
speedup_ort 5.669406 3.049341 2.12327 0.973638 0.489229
speedup_numpy 1.690328 0.939102 0.939098 1.58024 0.738059
speedup_ort-bind 3.288333 1.795696 1.449899 0.877093 0.452846
Total running time of the script: ( 0 minutes 11.956 seconds)