Inference with onnxruntime in Python¶
Simple case¶
The main class is InferenceSession. It loads an ONNX graph executes all the nodes in it.
<<<
import numpy
from onnxruntime import InferenceSession
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from skl2onnx import to_onnx
# creation of an ONNX graph
data = load_diabetes()
X, y = data.data, data.target
X_train, X_test, y_train, __ = train_test_split(X, y, random_state=11)
clr = LinearRegression()
clr.fit(X_train, y_train)
model_def = to_onnx(clr, X_train)
# InferenceSession only accepts a file name or the serialized
# ONNX graph.
sess = InferenceSession(model_def.SerializeToString())
# Method run takes two inputs, first one is
# the list of desired outputs or None for all,
# second is the input tensors in a dictionary
result = sess.run(None, {'X': X_test[:5]})
print(result)
with open("linreg_model.onnx", "wb") as f:
f.write(model_def.SerializeToString())
>>>
[array([[115.465],
[ 83.459],
[160.777],
[187.657],
[ 72.721]])]
And visually:
Some informations about the graph can be retrieved through the class InferenceSession such as inputs and outputs.
<<<
from onnxruntime import InferenceSession
sess = InferenceSession("linreg_model.onnx")
for t in sess.get_inputs():
print("input:", t.name, t.type, t.shape)
for t in sess.get_outputs():
print("output:", t.name, t.type, t.shape)
>>>
input: X tensor(double) [None, 10]
output: variable tensor(double) [None, 1]
The class InferenceSession is not pickable. It must be restored from the ONNX file. C API is slightly different. The C object is stored in attribute _sess.
<<<
import numpy
from onnxruntime import InferenceSession, RunOptions
X = numpy.random.randn(5, 10).astype(numpy.float64)
sess = InferenceSession("linreg_model.onnx")
names = [o.name for o in sess._sess.outputs_meta]
ro = RunOptions()
result = sess._sess.run(names, {'X': X}, ro)
print(result)
>>>
[array([[-2156.233],
[-1256.181],
[ -491.116],
[ 57.193],
[ 624.287]])]
Session Options¶
Many options can change the behaviour of the class during predictions. First class is SessionOptions. Next sections describe some of the members. This class can also be used to profile the execution or adjust graph optimization. This will be seen in further sections. Next sections just give an overview, you should go to classes SessionOptions and RunOptions to get the full list.
from onnxruntime import InferenceSession, SessionOptions
so = SessionOptions()
# so.... =
sess = InferenceSession(...., so)
logging¶
Parameters log_severity_level and log_verbosity_level may change the verbosity level when the model is loaded.
The logging during execution can be modified with the same attributes but in class RunOptions. This class is given to method run.
memory¶
onnxruntime focuses on efficiency first and memory peaks. Following what should be the priority, following members may be changed to trade efficiency against memory usage.
enable_cpu_mem_arena: Enables the memory arena on CPU. Arena may pre-allocate memory for future usage. Set this option to false if you don’t want it. Default is True.
enable_mem_pattern: Enable the memory pattern optimization. Default is true.
enable_mem_reuse: Enable the memory reuse optimization. Default is true.
multithreading¶
By default, onnxruntime parallelizes the execution within every node but does not run multiple node at the same time. But that can be changed.
inter_op_num_threads: Sets the number of threads used to parallelize the execution of the graph (across nodes). Default is 0 to let onnxruntime choose.
intra_op_num_threads: Sets the number of threads used to parallelize the execution within nodes. Default is 0 to let onnxruntime choose.
extensions¶
Attribute register_custom_ops_library to register an assembly implementing the runtime for custom nodes. onnxruntime-extensions is one of these extensions mostly focusing on text processing (tokenizers) or simple text manipulations. An exemple can be seen in section Custom runtime.
Providers¶
A provider is usually a list of implementation of ONNX operator for a specific environment. CPUExecutionProvider provides implementations for all operator on CPU. CUDAExecutionProvider does the same for GPU and the CUDA drivers. The list of all providers depends on the compilation settings. The list of available providers is a subset which depends on the machine onnxruntime is running on.
<<<
import pprint
import onnxruntime
print("all providers")
pprint.pprint(onnxruntime.get_all_providers())
print("available providers")
pprint.pprint(onnxruntime.get_available_providers())
>>>
all providers
['TensorrtExecutionProvider',
'CUDAExecutionProvider',
'MIGraphXExecutionProvider',
'ROCMExecutionProvider',
'OpenVINOExecutionProvider',
'DnnlExecutionProvider',
'NupharExecutionProvider',
'TvmExecutionProvider',
'VitisAIExecutionProvider',
'NnapiExecutionProvider',
'CoreMLExecutionProvider',
'ArmNNExecutionProvider',
'ACLExecutionProvider',
'DmlExecutionProvider',
'RknpuExecutionProvider',
'CPUExecutionProvider']
available providers
['CPUExecutionProvider']
onnxruntime selects CPUExecutionProvider if it is the only one available. It raises an exception if there are more. It is possible to select which provider must be used for the execution by filling argument providers:
sess = InferenceSession(
...
providers=['CUDAExecutionProvider', # first one takes precedence
'CPUExecutionProvider']
...)
All operators are not available in all providers, using multiple may improve the processing time. Switching from one provider to another may mean moving data from one memory manager to another, like the transition from CPU to CUDA or the other way.
Inference on a device different from CPU¶
By default, everything happens on CPU. Next lines show how to do computation on GPU with onnxruntime. Method run was using numpy arrays, another method is needed to use another device. The choice is not unique.
C_OrtValue¶
Method run_with_ort_values works the same way as run. Next example shows how to call the API with any OrtValue whatever the device it is stored on.
<<<
import numpy
from onnxruntime import InferenceSession
from onnxruntime.capi._pybind_state import ( # pylint: disable=E0611
OrtDevice as C_OrtDevice,
OrtValue as C_OrtValue,
OrtMemType)
sess = InferenceSession("linreg_model.onnx")
X = numpy.random.randn(5, 10).astype(numpy.float64)
device = C_OrtDevice(C_OrtDevice.cpu(), OrtMemType.DEFAULT, 0)
ort_X = C_OrtValue.ortvalue_from_numpy(X, device)
names = [o.name for o in sess._sess.outputs_meta]
result = sess._sess.run_with_ort_values({'X': ort_X}, names, None)
print(result[0].numpy())
>>>
[[ -16.338]
[ 811.287]
[-158.325]
[ -70.583]
[ 48.877]]
IOBinding¶
This API is slower than the previous one but is convenient when not all inputs change between two calls to the API. It relies on an intermediate structure SessionIOBinding. The structure is used to bind an array knowing its shape, its type, its address, to an input name.
<<<
import numpy
from onnxruntime import InferenceSession
from onnxruntime.capi._pybind_state import ( # pylint: disable=E0611
OrtDevice as C_OrtDevice,
OrtValue as C_OrtValue,
OrtMemType, SessionIOBinding)
sess = InferenceSession("linreg_model.onnx")
X = numpy.random.randn(5, 10).astype(numpy.float64)
bind = SessionIOBinding(sess._sess)
device = C_OrtDevice(C_OrtDevice.cpu(), OrtMemType.DEFAULT, 0)
# Next line binds the array to the input name.
bind.bind_input('X', device, X.dtype, X.shape,
X.__array_interface__['data'][0])
# This line tells on which device the result should be stored.
bind.bind_output('variable', device)
# Inference.
sess._sess.run_with_iobinding(bind, None)
# Next line retrieves the outputs as a list of OrtValue.
result = bind.get_outputs()
# Conversion to numpy to see the result.
print(result[0].numpy())
>>>
[[ 1699.099]
[ -467.072]
[-1459.209]
[ 1224.883]
[-1047.112]]
When the input is an OrtValue, another method is available.
<<<
import numpy
from onnxruntime import InferenceSession
from onnxruntime.capi._pybind_state import ( # pylint: disable=E0611
OrtDevice as C_OrtDevice,
OrtValue as C_OrtValue,
OrtMemType, SessionIOBinding)
sess = InferenceSession("linreg_model.onnx")
X = numpy.random.randn(5, 10).astype(numpy.float64)
bind = SessionIOBinding(sess._sess)
device = C_OrtDevice(C_OrtDevice.cpu(), OrtMemType.DEFAULT, 0)
# Next line was changed.
ort_X = C_OrtValue.ortvalue_from_numpy(X, device)
bind.bind_ortvalue_input('X', ort_X)
bind.bind_output('variable', device)
sess._sess.run_with_iobinding(bind, None)
result = bind.get_outputs()
print(result[0].numpy())
>>>
[[-1303.654]
[-1296.225]
[ 922.019]
[ 594.577]
[ -77.146]]
The last example binds the output to avoid a copy of the results. It gives an existing and allocated OrtValue which receives this output, as if it was inplace.
<<<
import numpy
from onnxruntime import InferenceSession
from onnxruntime.capi._pybind_state import ( # pylint: disable=E0611
OrtDevice as C_OrtDevice,
OrtValue as C_OrtValue,
OrtMemType, SessionIOBinding)
sess = InferenceSession("linreg_model.onnx")
X = numpy.random.randn(5, 10).astype(numpy.float64)
prediction = numpy.random.randn(5, 1).astype(numpy.float64)
bind = SessionIOBinding(sess._sess)
device = C_OrtDevice(C_OrtDevice.cpu(), OrtMemType.DEFAULT, 0)
ort_X = C_OrtValue.ortvalue_from_numpy(X, device)
bind.bind_ortvalue_input('X', ort_X)
# This line tells on which device the result should be stored.
ort_prediction = C_OrtValue.ortvalue_from_numpy(prediction, device)
bind.bind_ortvalue_output('variable', ort_prediction)
# Inference.
sess._sess.run_with_iobinding(bind, None)
# Result.
print(prediction)
>>>
[[-1184.846]
[ -102.396]
[ 360.741]
[ 196.061]
[ 291.23 ]]
Profiling¶
onnxruntime offers the possibility to profile the execution of a graph. It measures the time spent in each operator. The user starts the profiling when creating an instance of InferenceSession and stops it with method end_profiling. It stores the results as a json file whose name is returned by the method. The end of the example uses a tool to convert the json into a table.
<<<
import json
import numpy
from pandas import DataFrame
from onnxruntime import InferenceSession, RunOptions, SessionOptions
from sklearn.datasets import make_classification
from sklearn.cluster import KMeans
from skl2onnx import to_onnx
from mlprodict.onnxrt.ops_whole.session import OnnxWholeSession
# creation of an ONNX graph.
X, y = make_classification(100000)
km = KMeans(max_iter=10)
km.fit(X)
onx = to_onnx(km, X[:1].astype(numpy.float32))
# creation of a session that enables the profiling
so = SessionOptions()
so.enable_profiling = True
sess = InferenceSession(onx.SerializeToString(), so)
# execution
for i in range(0, 111):
sess.run(None, {'X': X.astype(numpy.float32)}, )
# profiling ends
prof = sess.end_profiling()
# and is collected in that file:
print(prof)
# what does it look like?
with open(prof, "r") as f:
js = json.load(f)
print(js[:3])
# a tool to convert it into a table
df = DataFrame(OnnxWholeSession.process_profiling(js))
# it has the following columns
print(df.columns)
# and looks this way
print(df.head(n=10))
df.to_csv("inference_profiling.csv", index=False)
>>>
onnxruntime_profile__2022-02-17_15-07-45.json
[{'cat': 'Session', 'pid': 2196, 'tid': 15368, 'dur': 662, 'ts': 6, 'ph': 'X', 'name': 'model_loading_array', 'args': {}}, {'cat': 'Session', 'pid': 2196, 'tid': 15368, 'dur': 5441, 'ts': 711, 'ph': 'X', 'name': 'session_initialization', 'args': {}}, {'cat': 'Node', 'pid': 2196, 'tid': 15368, 'dur': 1, 'ts': 12243, 'ph': 'X', 'name': 'Re_ReduceSumSquare_fence_before', 'args': {'op_name': 'ReduceSumSquare'}}]
Index(['cat', 'pid', 'tid', 'dur', 'ts', 'ph', 'name', 'args_op_name',
'args_provider', 'args_graph_index', 'args_parameter_size',
'args_thread_scheduling_stats', 'args_exec_plan_index',
'args_activation_size', 'args_output_size'],
dtype='object')
cat pid ... args_activation_size args_output_size
0 Session 2196 ... NaN NaN
1 Session 2196 ... NaN NaN
2 Node 2196 ... NaN NaN
3 Node 2196 ... 8000000 400000
4 Node 2196 ... NaN NaN
5 Node 2196 ... NaN NaN
6 Node 2196 ... 400000 400000
7 Node 2196 ... NaN NaN
8 Node 2196 ... NaN NaN
9 Node 2196 ... 8400000 3200000
[10 rows x 15 columns]
import os
import pandas
import matplotlib.pyplot as plt
full_name = os.path.normpath(os.path.abspath(
os.path.join("..", "..", "inference_profiling.csv")))
df = pandas.read_csv(full_name)
# but a graph is usually better...
gr_dur = df[['dur', "args_op_name"]].groupby("args_op_name").sum().sort_values('dur')
gr_n = df[['dur', "args_op_name"]].groupby("args_op_name").count().sort_values('dur')
gr_n = gr_n.loc[gr_dur.index, :]
fig, ax = plt.subplots(1, 3, figsize=(8, 4))
gr_dur.plot.barh(ax=ax[0])
gr_dur /= gr_dur['dur'].sum()
gr_dur.plot.barh(ax=ax[1])
gr_n.plot.barh(ax=ax[2])
ax[0].set_title("duration")
ax[1].set_title("proportion")
ax[2].set_title("n occurences");
for a in ax:
a.legend().set_visible(False)
plt.show()
(Source code, png, hires.png, pdf)
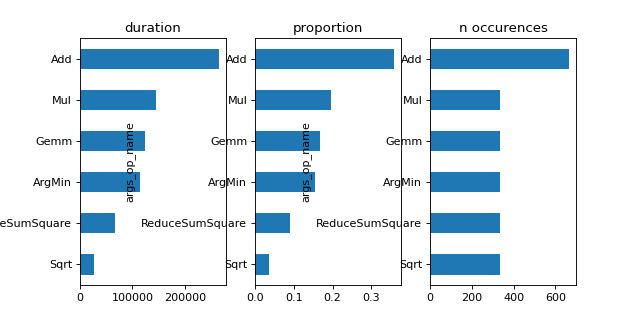{kind=link}
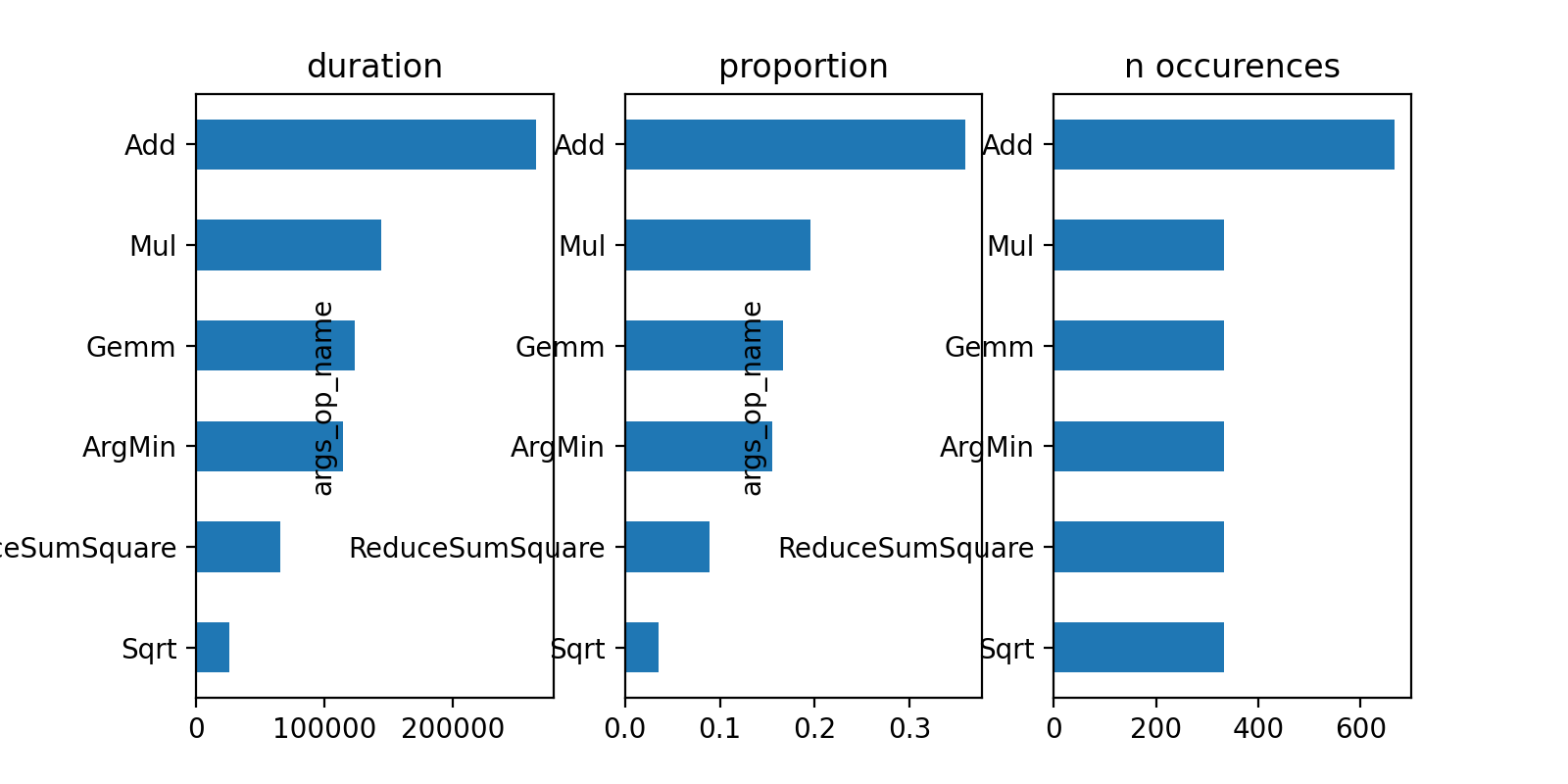{kind=link}
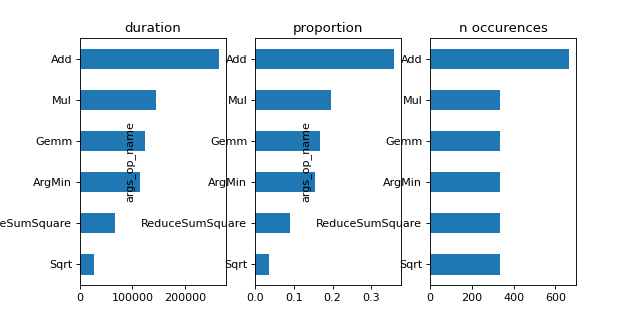
Graph Optimisations¶
By default, onnxruntime optimizes an ONNX graph as much as it can. It removes every node it can, merges duplicated initializers, fuses nodes into more complex node but more efficient such as FusedMatMul which deals with transposition as well. There are four level of optimization and the final can be saved on a disk to look at it.
so = SessionOptions()
so.graph_optimization_level = GraphOptimizationLevel.ORT_DISABLE_ALL
# or GraphOptimizationLevel.ORT_ENABLE_BASIC
# or GraphOptimizationLevel.ORT_ENABLE_EXTENDED
# or GraphOptimizationLevel.ORT_ENABLE_ALL
so.optimized_model_filepath = "to_save_the_optimized_onnx_file.onnx"
The bigger the graph is, the more efficient optimizations are.
Class InferenceSession as any other class from onnxruntime cannot be pickled. Everything can be created again from the ONNX file it loads. It also means graph optimization are computed again. To speed up the process, the optimized graph can be saved and loaded with disabled optimization next time. It can save the optimization time.