Note
Go to the end to download the full example code.
Measures loading and saving time for an ONNX model#
This script builds a small ONNX model and benchmarks the time to load
and save it using onnx, onnx_light.onnx, and
onnxruntime.
When the standalone C++ example executables load_onnx_time,
load_onnx_light_time, and
save_onnx_light_time are available, it also includes their timing output.
The model structure is identical in all cases.
Use --model <path> on the command line to benchmark an existing ONNX file
instead of the default synthetic model. The script also prints a short
statistics block (node count, initializer count, total tensor size, etc.)
for whichever model is used.
The onnx_light.onnx implementation does not depend on protobuf and
therefore avoids the overhead of the protobuf serialization layer.
It also supports parallel loading of tensor weights through the
num_threads keyword and loading models stored with external data.
When loading a single-file model, onnx_light.onnx memory-maps the
.onnx file (mmap on POSIX, CreateFileMapping on Windows) and
parses directly out of the mapped region — there is no double-buffered
ifstream + read-ahead step on top of it. The same memory-mapping
strategy is used for the external weights file when a model is stored
with external data: each weights file is mapped once into a shared buffer
that all tensors point into.
This brings load/1filex1/onnxlight-cpp close to (or ahead of)
load/1filex1/onnx-cpp on parser-bound models with many small
initializers. When no_copy=True is requested with a single-file
model the loader still copies inline raw_data (so that the parsed
ModelProto does not depend on the lifetime of the mmap region):
zero-copy of inline raw data is supported only for bytes inputs and
for external weights files.
One key advantage over the onnx package is zero-copy parsing:
when no_copy=True is passed to onnx_light.onnx.load() (or via
ParseOptions), tensor raw_data blobs are
not copied into new buffers. Instead each TensorProto stores a
direct pointer into the serialized bytes. This eliminates one
malloc + memcpy per tensor initializer and is therefore especially
beneficial for models with many large weight tensors.
For models stored with external data, no_copy=True enables a related
fast path: each external weights file is read once into a shared buffer,
and every tensor points into that shared storage instead of owning a
separate copy.
Warning
When no_copy=True is used with an in-memory bytes object,
the caller must keep that original buffer alive for as long as the
parsed model is in use. External-data files do not have that
lifetime constraint because onnx_light keeps the shared file
buffers alive.
For onnxruntime, the session is created with all graph optimizations
disabled (ORT_DISABLE_ALL) so that the measurement reflects only the
model loading overhead rather than compilation or fusion costs.
onnx,onnxlight,ort: useonnx,onnx-light, oronnxruntime1filex1: saves in a single file with 1 thread1filex4: saves in a single file with 4 threads2filex1: saves in a file and another for external data with 1 thread2filex4: saves in a file and another for external data with 4 threads
Selectable benchmark scenarios (via --scenario):
load, save, serialize, parse, cpp, all.
The cpp scenario runs the standalone C++ timing executables
(load_onnx_time, load_onnx_light_time, save_onnx_light_time)
when they are available. The executable discovery automatically skips
them when the CI environment variable is set, so no results are
produced in CI environments where the executables have not been built.
Use --model <path> to supply an existing single-file ONNX model.
When provided the synthetic model is not created, and the supplied file
is used directly as the benchmark target. The external-data variant
(used for 2file benchmarks) is still derived from the loaded model
and written to the temporary directory.
Alternatively, use --model-id <huggingface_repo_id> to download an
ONNX model from the Hugging Face Hub and
benchmark it. For example, --model-id onnx-community/Qwen3-0.6B-ONNX
downloads onnx-community/Qwen3-0.6B-ONNX. The specific
file to download inside the repository can be selected with
--model-file (default onnx/model.onnx). When the download
fails (for example due to a connectivity issue) the script prints a
warning and falls back to the default synthetic model so the example
can still run in offline environments.
import argparse
import math
import os
import pathlib
import re
import shutil
import tempfile
import time
import urllib.error
import urllib.request
import numpy as np
import pandas
import onnx
import onnx.helper as oh
import onnx.numpy_helper as onh
import onnxruntime as ort
_ort_sess_opts = ort.SessionOptions()
_ort_sess_opts.graph_optimization_level = ort.GraphOptimizationLevel.ORT_DISABLE_ALL
import onnx_light.onnx as onnxl
import onnx_light.onnx_lib.helper as onnxlh
from onnx_light.doc import (
find_standalone_executable,
get_processor_name,
get_total_memory_gb,
measure_cpp_with_example,
)
Setup#
Define benchmark parameters and command-line argument parsers. Use –model <path> to benchmark an existing ONNX file instead of the default synthetic model built from make_model().
N_INIT = 40
DIM = 256 if os.environ.get("UNITTEST_GOING") == "1" else 2048
BENCHMARK_SCENARIOS = ("load", "save", "serialize", "parse", "cpp")
def _parse_benchmark_scenarios(args=None) -> set[str]:
"""Parses command-line arguments and returns the selected benchmark scenarios."""
parser = argparse.ArgumentParser(
description="Runs one or several benchmark scenarios for plot_onnx_time.py."
)
parser.add_argument(
"--scenario",
dest="scenarios",
action="append",
choices=(*BENCHMARK_SCENARIOS, "all"),
help=(
"Scenario to execute. May be specified multiple times. "
"Supported values: load, save, serialize, parse, cpp, all."
),
)
parsed, _ = parser.parse_known_args(args=args)
values = parsed.scenarios or ["all"]
if "all" in values:
return set(BENCHMARK_SCENARIOS)
return set(values)
def _parse_model_path(args=None) -> str | None:
"""Parses the ``--model`` command-line argument and returns the path.
Returns:
Path to an existing ONNX model file, or ``None`` if not provided.
"""
parser = argparse.ArgumentParser(add_help=False)
parser.add_argument(
"--model",
dest="model_path",
default=None,
help=(
"Path to an existing single-file ONNX model to benchmark "
"instead of the default synthetic model."
),
)
parsed, _ = parser.parse_known_args(args=args)
return parsed.model_path
def _parse_model_id(args=None) -> tuple[str | None, str]:
"""Parses the ``--model-id`` and ``--model-file`` command-line arguments.
Returns:
A tuple ``(model_id, model_file)`` where ``model_id`` is the
Hugging Face repository identifier (or ``None`` when not given)
and ``model_file`` is the path within the repository of the ONNX
file to download (defaults to ``onnx/model.onnx``).
"""
parser = argparse.ArgumentParser(add_help=False)
parser.add_argument(
"--model-id",
dest="model_id",
default=None,
help=(
"Hugging Face repository id (e.g. onnx-community/Qwen3-0.6B-ONNX) "
"from which to download an ONNX model to benchmark."
),
)
parser.add_argument(
"--model-file",
dest="model_file",
default="onnx/model.onnx",
help=(
"Path within the Hugging Face repository of the ONNX file to "
"download when --model-id is provided. Defaults to onnx/model.onnx."
),
)
parsed, _ = parser.parse_known_args(args=args)
return parsed.model_id, parsed.model_file
def _download_hf_model(model_id: str, model_file: str, dest_dir: str) -> str | None:
"""Downloads an ONNX model file from the Hugging Face Hub.
The file is fetched from
``https://huggingface.co/{model_id}/resolve/main/{model_file}`` and
written under *dest_dir*. Any download failure (network error,
HTTP error, OS error, ...) is caught and reported with a warning;
the function then returns ``None`` so that callers can fall back to
a default model.
Args:
model_id: Hugging Face repository identifier.
model_file: Path of the ONNX file inside the repository.
dest_dir: Directory in which to write the downloaded file.
Returns:
Absolute path to the downloaded file, or ``None`` when the
download failed.
"""
url = f"https://huggingface.co/{model_id}/resolve/main/{model_file}"
local_path = os.path.abspath(os.path.join(dest_dir, os.path.basename(model_file)))
os.makedirs(os.path.dirname(local_path) or ".", exist_ok=True)
print(f"Downloading {url} -> {local_path}")
try:
urllib.request.urlretrieve(url, local_path) # noqa: S310
except (urllib.error.URLError, urllib.error.HTTPError, OSError, ValueError) as exc:
print(
f"WARNING: failed to download {url}: {exc}. "
"Falling back to the default synthetic model."
)
if os.path.exists(local_path):
try:
os.remove(local_path)
except OSError:
pass
return None
return local_path
SELECTED_SCENARIOS = _parse_benchmark_scenarios()
_CLI_MODEL_PATH = _parse_model_path()
_CLI_MODEL_ID, _CLI_MODEL_FILE = _parse_model_id()
def _run_scenario(name: str) -> bool:
"""Checks whether the given scenario name is selected for execution."""
return name in SELECTED_SCENARIOS
def make_model(n_init: int = N_INIT, dim: int = DIM) -> onnx.ModelProto:
"""Returns a synthetic ONNX model with *n_init* Gemm initializers of size *dim*."""
initializers = []
nodes = []
inputs = [oh.make_tensor_value_info("X", onnx.TensorProto.FLOAT, [None, dim])]
prev = "X"
for i in range(n_init):
weight_name = f"W{i}"
out_name = f"Y{i}"
w = np.random.randn(dim, dim).astype(np.float32)
initializers.append(onh.from_array(w, name=weight_name))
nodes.append(oh.make_node("Gemm", [prev, weight_name], [out_name], transB=1))
prev = out_name
outputs = [oh.make_tensor_value_info(prev, onnx.TensorProto.FLOAT, [None, dim])]
graph = oh.make_graph(nodes, "bench_graph", inputs, outputs, initializer=initializers)
model = oh.make_model(graph, opset_imports=[oh.make_opsetid("", 18)], ir_version=9)
return model
def _tensor_data_bytes(tensor: onnx.TensorProto) -> int:
"""Returns the in-memory byte count of a TensorProto's stored data.
Uses :func:`onnx_light.onnx_lib.helper.tensor_dtype_to_np_dtype` to map
the element type to a numpy dtype and derives the byte count from the
tensor dimensions, avoiding a full array materialisation.
Returns:
Byte count of the tensor's data, or ``0`` when it cannot be determined.
"""
if tensor.raw_data:
return len(tensor.raw_data)
if tensor.data_type not in onnxlh.TENSOR_TYPE_MAP:
return 0
np_dtype = onnxlh.tensor_dtype_to_np_dtype(tensor.data_type)
n_elements = math.prod(tensor.dims) if tensor.dims else 1
return int(np_dtype.itemsize * n_elements)
def print_model_stats(model: onnx.ModelProto, file_path: str | None = None) -> None:
"""Prints summary statistics for *model* to stdout.
Args:
model: The ONNX model to inspect.
file_path: Optional path to the model file on disk; when given the
file size is included in the output.
"""
graph = model.graph
n_nodes = len(graph.node)
n_initializers = len(graph.initializer)
n_inputs = len(graph.input)
n_outputs = len(graph.output)
total_tensor_bytes = sum(_tensor_data_bytes(t) for t in graph.initializer)
opsets = ", ".join(f"{op.domain or 'ai.onnx'}={op.version}" for op in model.opset_import)
print("Model statistics")
print("----------------")
print(f" IR version : {model.ir_version}")
print(f" Opset(s) : {opsets}")
print(f" Number of nodes : {n_nodes}")
print(f" Number of inputs : {n_inputs}")
print(f" Number of outputs : {n_outputs}")
print(f" Number of initializers : {n_initializers}")
print(f" Total initializer size : {total_tensor_bytes / 2 ** 20:.3f} MB")
if file_path and os.path.exists(file_path):
print(f" File size : {os.path.getsize(file_path) / 2 ** 20:.3f} MB")
print(f" Serialized model size : {model.ByteSize() / 2 ** 20:.3f} MB")
Model setup#
Either load an existing model supplied via --model or build the default
synthetic one and write it to a temporary directory.
tmp_dir = "temp_plot_onnx_time"
if not os.path.exists(tmp_dir):
os.mkdir(tmp_dir)
if _CLI_MODEL_PATH is not None:
onnx_path = os.path.abspath(_CLI_MODEL_PATH)
model = onnx.load(onnx_path)
print(f"Using provided model: {onnx_path}")
elif _CLI_MODEL_ID is not None:
downloaded = _download_hf_model(_CLI_MODEL_ID, _CLI_MODEL_FILE, tmp_dir)
if downloaded is not None:
onnx_path = downloaded
model = onnx.load(onnx_path)
print(f"Using model from Hugging Face id {_CLI_MODEL_ID!r}: {onnx_path}")
else:
model = make_model()
onnx_path = os.path.join(tmp_dir, "bench.onnx")
onnx.save(model, onnx_path)
else:
model = make_model()
onnx_path = os.path.join(tmp_dir, "bench.onnx")
onnx.save(model, onnx_path)
size_bytes = model.ByteSize()
print(f"Model size: {size_bytes / 2 ** 20:.3f} MB")
file_size = os.path.getsize(onnx_path)
print(f"File size : {file_size / 2 ** 20:.3f} MB")
onx = onnx.load(onnx_path)
onxl = onnxl.load(onnx_path)
onxl_x4 = onnxl.load(onnx_path, num_threads=4)
ext_load_onnx = os.path.abspath(os.path.join(tmp_dir, "ext_load.onnx"))
ext_load_data = os.path.abspath(os.path.join(tmp_dir, "ext_load.onnx.data"))
onnxl.save(onxl, ext_load_onnx, location=ext_load_data)
Model size: 640.002 MB
File size : 640.002 MB
Model statistics#
Print a summary of the model: number of nodes, initializers (tensors), total weight size, file size, and serialized size.
print_model_stats(model, onnx_path)
Model statistics
----------------
IR version : 9
Opset(s) : ai.onnx=18
Number of nodes : 40
Number of inputs : 1
Number of outputs : 1
Number of initializers : 40
Total initializer size : 640.000 MB
File size : 640.002 MB
Serialized model size : 640.002 MB
Benchmark helper.
MIN_TIME_THRESHOLD = 1e-9
CPP_LOAD_METRIC_PATTERN = re.compile(
r"^\s*(Average|Median|Min|Max|Std|Standard deviation) load \(ms\)\s*:\s*([0-9.eE+-]+)\s*$"
)
CPP_SAVE_METRIC_PATTERN = re.compile(
r"^\s*(Average|Median|Min|Max|Std|Standard deviation) save \(ms\)\s*:\s*([0-9.eE+-]+)\s*$"
)
WINDOWS_BUILD_CONFIGS = ("Release", "RelWithDebInfo", "Debug", "MinSizeRel")
def measure(name: str, fn, n: int = 5, warmup: int = 1) -> dict:
"""
Executes *fn* with warm-up iterations and records timing statistics.
Args:
name: Benchmark name.
fn: Callable to execute.
n: Number of measured iterations.
warmup: Number of non-measured warm-up iterations.
Returns:
A dictionary containing name, median, avg, min, max, and std.
"""
for _ in range(max(0, warmup)):
fn()
times = []
for _ in range(n):
t0 = time.perf_counter()
fn()
times.append(time.perf_counter() - t0)
arr = np.array(times)
return {
"name": name,
"median": float(np.median(arr)),
"avg": float(np.mean(arr)),
"min": float(np.min(arr)),
"max": float(np.max(arr)),
"std": float(np.std(arr)),
}
def _flush_file(path: str) -> None:
"""Flushes one file descriptor so benchmark timing includes write-back."""
with open(path, "r+b") as stream:
stream.flush()
os.fsync(stream.fileno())
def print_stats(name: str, stats: dict) -> None:
"""Prints timing statistics (average, median, max, and standard deviation) in milliseconds."""
print(
f"{name:<35} avg={stats['avg'] * 1e3:.1f} ms"
f" median={stats['median'] * 1e3:.1f} ms"
f" max={stats['max'] * 1e3:.1f} ms"
f" std={stats['std'] * 1e3:.1f} ms"
)
def _find_load_onnx_time_executable() -> str | None:
"""Locates the standalone C++ timing executable.
Returns:
The path to ``load_onnx_time`` if available, otherwise ``None``.
"""
return find_standalone_executable(
"load_onnx_time",
[
pathlib.Path("build/load-onnx-time-example/load_onnx_time"),
pathlib.Path("build/examples/load_onnx_time/load_onnx_time"),
pathlib.Path("build-load-onnx-time/load_onnx_time"),
],
script_file=globals().get("__file__"),
windows_build_configs=WINDOWS_BUILD_CONFIGS,
)
def _find_load_onnx_light_time_executable() -> str | None:
"""Locates the standalone ``load_onnx_light_time`` executable.
Returns:
The path to ``load_onnx_light_time`` if available, otherwise ``None``.
"""
return find_standalone_executable(
"load_onnx_light_time",
[
pathlib.Path("build/load-onnx-light-time-example/load_onnx_light_time"),
pathlib.Path("build/examples/load_onnx_light_time/load_onnx_light_time"),
pathlib.Path("build-load-onnx-light-time/load_onnx_light_time"),
],
script_file=globals().get("__file__"),
windows_build_configs=WINDOWS_BUILD_CONFIGS,
)
def _measure_cpp_load_with_example(
onnx_file: str,
n: int = 20,
num_threads: int = 1,
executable_name: str = "load_onnx_light_time",
file_count: int = 1,
no_copy: bool = False,
touch_raw_data_pages: bool = False,
) -> dict | None:
"""Measures C++ loading performance through a standalone executable.
Args:
onnx_file: Model path to pass to the standalone executable.
n: Number of iterations to pass to the standalone executable.
num_threads: Number of loading threads to pass to the standalone executable.
executable_name: Executable selector to use:
``"load_onnx_time"`` or ``"load_onnx_light_time"``.
file_count: Number of files involved in the benchmark key.
no_copy: Whether to request ``no_copy`` mode from ``load_onnx_light_time``.
touch_raw_data_pages: Whether to request page touching during no-copy loading
from ``load_onnx_light_time``.
Returns:
A benchmark dictionary matching :func:`measure` output keys if successful,
otherwise ``None``.
"""
if file_count <= 0:
raise ValueError(f"file_count must be positive, got {file_count!r}")
if executable_name == "load_onnx_time":
if no_copy:
raise ValueError("no_copy is only supported with 'load_onnx_light_time'")
executable = _find_load_onnx_time_executable()
result_name = f"load/{file_count}filex{num_threads}/onnx-cpp"
elif executable_name == "load_onnx_light_time":
executable = _find_load_onnx_light_time_executable()
lib_name = "onnxlight-cpp-nocopy" if no_copy else "onnxlight-cpp"
result_name = f"load/{file_count}filex{num_threads}/{lib_name}"
else:
raise ValueError(
"executable_name must be 'load_onnx_time' or "
f"'load_onnx_light_time', got {executable_name!r}"
)
args = [onnx_file, str(n), str(num_threads)]
if no_copy:
args.append("nocopy_touch" if touch_raw_data_pages else "nocopy")
return measure_cpp_with_example(
executable=executable,
args=args,
metric_pattern=CPP_LOAD_METRIC_PATTERN,
result_name=result_name,
executable_name=executable_name,
)
def _find_save_onnx_light_time_executable() -> str | None:
"""Locates the standalone C++ save-timing executable.
Returns:
The path to ``save_onnx_light_time`` if available, otherwise ``None``.
"""
return find_standalone_executable(
"save_onnx_light_time",
[
pathlib.Path("build/save-onnx-light-time-example/save_onnx_light_time"),
pathlib.Path("build/examples/save_onnx_light_time/save_onnx_light_time"),
pathlib.Path("build-save-onnx-light-time/save_onnx_light_time"),
],
script_file=globals().get("__file__"),
windows_build_configs=WINDOWS_BUILD_CONFIGS,
)
def _measure_cpp_save_with_example(
onnx_file: str, n: int = 20, num_threads: int = 1
) -> dict | None:
"""Measures C++ one-file save performance through ``save_onnx_light_time``.
Returns:
A benchmark dictionary matching :func:`measure` output keys if successful,
otherwise ``None``.
"""
executable = _find_save_onnx_light_time_executable()
if executable is None:
return None
with tempfile.TemporaryDirectory() as tmp_save_dir:
return measure_cpp_with_example(
executable=executable,
args=[onnx_file, tmp_save_dir, str(n), str(num_threads), "onefile"],
metric_pattern=CPP_SAVE_METRIC_PATTERN,
result_name=f"save/1filex{num_threads}/onnxlight-cpp",
executable_name="save_onnx_light_time",
)
# Load scenarios
# --------------
data = []
if _run_scenario("load"):
# %%
# Load with onnx.
data.append(measure("load/1filex1/onnx", lambda: onnx.load(onnx_path)))
print_stats("load/1filex1/onnx", data[-1])
# %%
# Load with ``onnx_light.onnx``.
data.append(measure("load/1filex1/onnxlight", lambda: onnxl.load(onnx_path)))
print_stats("load/1filex1/onnxlight", data[-1])
# %%
# Load with ``onnx_light.onnx`` using parallel tensor loading.
data.append(measure("load/1filex4/onnxlight", lambda: onnxl.load(onnx_path, num_threads=4)))
print_stats("load/1filex4/onnxlight", data[-1])
# %%
# Compare the two file-backed stream implementations explicitly:
# ``FileLoadMode.MMAP`` memory-maps the ``.onnx`` file (``mmap`` on POSIX,
# ``CreateFileMapping`` on Windows) and parses directly out of the mapped
# region, while ``FileLoadMode.IFSTREAM`` forces the buffered
# ``std::ifstream``-based reader. The default ``FileLoadMode.AUTO``
# behaves like ``MMAP`` for single-file models when ``no_copy`` is not
# requested; running both modes side by side highlights the gain (or
# cost) of memory mapping on the current platform/filesystem.
data.append(
measure(
"load/1filex1/onnxlight-mmap", lambda: onnxl.load(onnx_path, file_load_mode="MMAP")
)
)
print_stats("load/1filex1/onnxlight-mmap", data[-1])
data.append(
measure(
"load/1filex1/onnxlight-ifstream",
lambda: onnxl.load(onnx_path, file_load_mode="IFSTREAM"),
)
)
print_stats("load/1filex1/onnxlight-ifstream", data[-1])
# %%
# Load with ``onnxruntime`` (all optimizations disabled).
# ``InferenceSession`` is created with ``ORT_DISABLE_ALL`` so the
# measurement captures only model loading overhead, not graph optimization.
data.append(
measure(
"load/1filex1/ort",
lambda: ort.InferenceSession(onnx_path, sess_options=_ort_sess_opts),
)
)
print_stats("load/1filex1/ort", data[-1])
load/1filex1/onnx avg=166.7 ms median=166.8 ms max=167.8 ms std=0.9 ms
load/1filex1/onnxlight avg=94.8 ms median=94.8 ms max=95.4 ms std=0.4 ms
load/1filex4/onnxlight avg=53.7 ms median=53.8 ms max=55.3 ms std=1.3 ms
load/1filex1/onnxlight-mmap avg=96.0 ms median=95.9 ms max=96.8 ms std=0.6 ms
load/1filex1/onnxlight-ifstream avg=108.7 ms median=108.6 ms max=108.9 ms std=0.1 ms
load/1filex1/ort avg=381.1 ms median=384.1 ms max=387.5 ms std=5.5 ms
Serialize and Parse benchmarks#
def _serialize_onnx() -> bytes:
"""Serializes the ONNX model to bytes."""
return onx.SerializeToString()
def _serialize_onnxlight() -> bytes:
"""Serializes the onnx_light model to bytes."""
return onxl.SerializeToString()
def _serialize_onnxlight_x4() -> bytes:
"""Serializes the onnx_light model in parallel to bytes."""
return onxl.SerializeToString(opts_serial_x4)
if _run_scenario("serialize"):
opts_serial_x4 = onnxl.SerializeOptions()
opts_serial_x4.num_threads = 4
assert len(_serialize_onnx()) > 0
assert len(_serialize_onnxlight()) > 0
assert len(_serialize_onnxlight_x4()) > 0
data.append(measure("serialize/x1/onnx", _serialize_onnx))
print_stats("serialize/x1/onnx", data[-1])
data.append(measure("serialize/x1/onnxlight", _serialize_onnxlight))
print_stats("serialize/x1/onnxlight", data[-1])
data.append(measure("serialize/x4/onnxlight", _serialize_onnxlight_x4))
print_stats("serialize/x4/onnxlight", data[-1])
serialize/x1/onnx avg=384.1 ms median=383.7 ms max=386.9 ms std=1.6 ms
serialize/x1/onnxlight avg=388.4 ms median=388.2 ms max=389.7 ms std=0.7 ms
serialize/x4/onnxlight avg=396.6 ms median=393.6 ms max=406.3 ms std=6.9 ms
ParseFromString comparison between onnx and onnx_light.onnx.
def _parse_onnx() -> onnx.ModelProto:
"""Parses ONNX bytes into a ModelProto."""
parsed = onnx.ModelProto()
parsed.ParseFromString(serialized_onnx)
return parsed
def _parse_onnxlight() -> onnxl.ModelProto:
"""Parses onnx_light bytes into a ModelProto."""
parsed = onnxl.ModelProto()
parsed.ParseFromString(serialized_onnxlight)
return parsed
def _parse_onnxlight_x4() -> onnxl.ModelProto:
"""Parses onnx_light bytes in parallel into a ModelProto."""
parsed = onnxl.ModelProto()
parsed.ParseFromString(serialized_onnxlight, opts_parse_x4)
return parsed
def _parse_onnxlight_nc() -> onnxl.ModelProto:
"""Parses onnx_light bytes without copying raw tensor data (zero-copy)."""
parsed = onnxl.ModelProto()
parsed.ParseFromString(serialized_onnxlight, opts_parse_nc)
return parsed
def _parse_onnxlight_nc_x4() -> onnxl.ModelProto:
"""Parses onnx_light bytes in parallel without copying raw tensor data (zero-copy, 4 t)."""
parsed = onnxl.ModelProto()
parsed.ParseFromString(serialized_onnxlight, opts_parse_nc_x4)
return parsed
if _run_scenario("parse"):
serialized_onnx = onx.SerializeToString()
serialized_onnxlight = onxl.SerializeToString()
opts_parse_x4 = onnxl.ParseOptions()
opts_parse_x4.num_threads = 4
opts_parse_nc = onnxl.ParseOptions()
opts_parse_nc.no_copy = True
opts_parse_nc_x4 = onnxl.ParseOptions()
opts_parse_nc_x4.no_copy = True
opts_parse_nc_x4.num_threads = 4
parsed_onnx = _parse_onnx()
assert parsed_onnx.ir_version == onx.ir_version
assert len(parsed_onnx.graph.node) == len(onx.graph.node)
parsed_onnxlight = _parse_onnxlight()
assert parsed_onnxlight.ir_version == onxl.ir_version
assert len(parsed_onnxlight.graph.node) == len(onxl.graph.node)
parsed_onnxlight_x4 = _parse_onnxlight_x4()
assert parsed_onnxlight_x4.ir_version == onxl.ir_version
assert len(parsed_onnxlight_x4.graph.node) == len(onxl.graph.node)
parsed_onnxlight_nc = _parse_onnxlight_nc()
assert parsed_onnxlight_nc.ir_version == onxl.ir_version
assert len(parsed_onnxlight_nc.graph.node) == len(onxl.graph.node)
parsed_onnxlight_nc_x4 = _parse_onnxlight_nc_x4()
assert parsed_onnxlight_nc_x4.ir_version == onxl.ir_version
assert len(parsed_onnxlight_nc_x4.graph.node) == len(onxl.graph.node)
data.append(measure("parse/x1/onnx", _parse_onnx))
print_stats("parse/x1/onnx", data[-1])
data.append(measure("parse/x1/onnxlight", _parse_onnxlight))
print_stats("parse/x1/onnxlight", data[-1])
data.append(measure("parse/x4/onnxlight", _parse_onnxlight_x4))
print_stats("parse/x4/onnxlight", data[-1])
# %%
# Parse with zero-copy (``no_copy=True``): raw tensor data is not copied.
# The pointer inside each TensorProto points directly into ``serialized_onnxlight``.
# The bytes object **must** remain alive for as long as the parsed model is used.
data.append(measure("parse/nc/onnxlight", _parse_onnxlight_nc))
print_stats("parse/nc/onnxlight", data[-1])
# %%
# Parse with zero-copy **and** parallel tensor reads (``no_copy=True, num_threads=4``).
# Combines the allocation savings of zero-copy with multi-threaded I/O for large models.
data.append(measure("parse/ncx4/onnxlight", _parse_onnxlight_nc_x4))
print_stats("parse/ncx4/onnxlight", data[-1])
parse/x1/onnx avg=96.9 ms median=95.1 ms max=102.7 ms std=3.1 ms
parse/x1/onnxlight avg=97.5 ms median=97.6 ms max=98.3 ms std=0.8 ms
parse/x4/onnxlight avg=54.0 ms median=54.4 ms max=54.9 ms std=1.0 ms
parse/nc/onnxlight avg=0.0 ms median=0.0 ms max=0.0 ms std=0.0 ms
parse/ncx4/onnxlight avg=0.2 ms median=0.2 ms max=0.2 ms std=0.0 ms
Save benchmarks#
Save once with external data (not benchmarked) using onnx_light.onnx so
that the in-memory model is not modified (ClearExternalData restores it
after the C++ write).
Absolute paths ensure onnxlight stores only the basename in the .onnx
metadata, letting both onnx.load and onnxl.load resolve the data
file automatically.
if _run_scenario("save"):
# %%
# Save with ``onnx``.
out_onnx = os.path.join(tmp_dir, "out_onnx.onnx")
data.append(measure("save/1filex1/onnx", lambda: onnx.save(onx, out_onnx)))
print_stats("save/1filex1/onnx", data[-1])
# %%
# Save with ``onnx`` using external data.
# This is the slow path: Python iterates every tensor, creates a numpy
# intermediate, and calls Python I/O for each weight blob.
out_onnx_ext = os.path.join(tmp_dir, "out_onnx_ext.onnx")
out_onnx_ext_location = "out_onnx_ext.data"
out_onnx_ext_data = os.path.join(tmp_dir, out_onnx_ext_location)
def _save_onnx_external_with_flush() -> None:
onnx.save_model(
onx,
out_onnx_ext,
save_as_external_data=True,
all_tensors_to_one_file=True,
location=out_onnx_ext_location,
)
_flush_file(out_onnx_ext_data)
_flush_file(out_onnx_ext)
data.append(measure("save/2filex1/onnx", _save_onnx_external_with_flush, n=1, warmup=0))
print_stats("save/2filex1/onnx", data[-1])
# %%
# The onnx file is modified to store the external data.
# Let's make sure it is not used again.
onx = None
# %%
# Save with ``onnx_light.onnx``.
out_onnxl = os.path.join(tmp_dir, "out_onnxlight.onnx")
data.append(measure("save/1filex1/onnxlight", lambda: onnxl.save(onxl, out_onnxl)))
print_stats("save/1filex1/onnxlight", data[-1])
# %%
# Save with ``onnx_light.onnx`` parallelized.
out_onnxl_x4 = os.path.join(tmp_dir, "out_onnxlight_x4.onnx")
data.append(
measure(
"save/1filex4/onnxlight", lambda: onnxl.save(onxl_x4, out_onnxl_x4, num_threads=4)
)
)
print_stats("save/1filex4/onnxlight", data[-1])
# %%
# Save with ``onnx_light.onnx`` using external data.
# All work is done in C++: ``PopulateExternalData`` attaches metadata once,
# ``SerializeToStream`` routes large ``raw_data`` blobs directly to the
# weights file via ``TwoFilesWriteStream``, and ``ClearExternalData``
# restores the in-memory model. No numpy arrays are created.
# As for the ``onnx`` row, the two output files are explicitly ``fsync``-ed
# so both benchmarks include descriptor flush/write-back costs.
# The main ``.onnx`` structure is accumulated in a ``StringWriteStream``
# (memory buffer) and flushed to disk in a single write after all tensor
# data has been written, mirroring the sequential I/O pattern used by
# ``onnx.save_model`` and allowing OS-level write coalescing.
out_ext = os.path.join(tmp_dir, "out_ext.onnx")
out_ext_data = out_ext + ".data"
def _save_onnxlight_external_with_flush() -> None:
onnxl.save(onxl, out_ext, location=out_ext_data)
_flush_file(out_ext_data)
_flush_file(out_ext)
data.append(measure("save/2filex1/onnxlight", _save_onnxlight_external_with_flush))
print_stats("save/2filex1/onnxlight", data[-1])
# %%
# Save with ``onnx_light.onnx`` using external data parallelized.
out_ext_x4 = os.path.join(tmp_dir, "out_ext_x4.onnx")
out_ext_x4_data = out_ext_x4 + ".data"
data.append(
measure(
"save/2filex4/onnxlight",
lambda: onnxl.save(onxl, out_ext_x4, location=out_ext_x4_data, num_threads=4),
)
)
print_stats("save/2filex4/onnxlight", data[-1])
save/1filex1/onnx avg=1810.3 ms median=1653.6 ms max=2156.6 ms std=262.6 ms
save/2filex1/onnx avg=2100.3 ms median=2100.3 ms max=2100.3 ms std=0.0 ms
save/1filex1/onnxlight avg=1477.0 ms median=1592.0 ms max=1742.6 ms std=297.4 ms
save/1filex4/onnxlight avg=256.2 ms median=208.2 ms max=449.0 ms std=96.4 ms
save/2filex1/onnxlight avg=1716.4 ms median=1644.1 ms max=2092.0 ms std=189.4 ms
save/2filex4/onnxlight avg=208.1 ms median=206.6 ms max=214.4 ms std=3.2 ms
C++ benchmarks#
Run the standalone C++ benchmark executables when available.
These scenarios measure the same operations as load and save
but use the compiled C++ timing executables directly, bypassing the
Python interpreter overhead entirely.
if _run_scenario("cpp"):
# %%
# Load with standalone C++ ``load_onnx_light_time`` example when available.
# The executable uses ``FileStream`` as well, so this row measures the same
# file-backed parsing path as ``onnxl.load(onnx_path)``.
cpp_load_x1 = _measure_cpp_load_with_example(onnx_path, num_threads=1)
if cpp_load_x1 is not None:
data.append(cpp_load_x1)
print_stats(cpp_load_x1["name"], cpp_load_x1)
else:
print(
"load_onnx_light_time executable not found (or failed), skipping C++ load benchmark."
)
cpp_load_x4 = _measure_cpp_load_with_example(onnx_path, num_threads=4)
if cpp_load_x4 is not None:
data.append(cpp_load_x4)
print_stats(cpp_load_x4["name"], cpp_load_x4)
# %%
# Load an external-data model with standalone C++ ``load_onnx_light_time``
# using ``no_copy`` shared external buffers.
cpp_load_ext_nc = _measure_cpp_load_with_example(
ext_load_onnx, num_threads=1, file_count=2, no_copy=True, touch_raw_data_pages=True
)
if cpp_load_ext_nc is not None:
data.append(cpp_load_ext_nc)
print_stats(cpp_load_ext_nc["name"], cpp_load_ext_nc)
# %%
# Load with standalone C++ ``load_onnx_time`` example when available.
# The executable uses the standard onnx protobuf library for loading.
cpp_load_onnx_x1 = _measure_cpp_load_with_example(
onnx_path, num_threads=1, executable_name="load_onnx_time"
)
if cpp_load_onnx_x1 is not None:
data.append(cpp_load_onnx_x1)
print_stats(cpp_load_onnx_x1["name"], cpp_load_onnx_x1)
else:
print("load_onnx_time executable not found (or failed), skipping C++ load benchmark.")
# %%
# Save with standalone C++ ``save_onnx_light_time`` example when available.
cpp_save_x1 = _measure_cpp_save_with_example(onnx_path, num_threads=1)
if cpp_save_x1 is not None:
data.append(cpp_save_x1)
print_stats(cpp_save_x1["name"], cpp_save_x1)
else:
print(
"save_onnx_light_time executable not found (or failed), skipping C++ save benchmark."
)
cpp_save_x4 = _measure_cpp_save_with_example(onnx_path, num_threads=4)
if cpp_save_x4 is not None:
data.append(cpp_save_x4)
print_stats(cpp_save_x4["name"], cpp_save_x4)
load_onnx_light_time executable not found (or failed), skipping C++ load benchmark.
load_onnx_time executable not found (or failed), skipping C++ load benchmark.
save_onnx_light_time executable not found (or failed), skipping C++ save benchmark.
Load with onnx using external data#
Reload the model previously saved with external data using onnx.load.
if _run_scenario("load"):
data.append(
measure("load/2filex1/onnx", lambda: onnx.load(ext_load_onnx, load_external_data=True))
)
print_stats("load/2filex1/onnx", data[-1])
# %%
# Load with ``onnx_light.onnx`` using external data.
# Reload the same external-data model using ``onnxl.load``.
data.append(
measure(
"load/2filex1/onnxlight", lambda: onnxl.load(ext_load_onnx, location=ext_load_data)
)
)
print_stats("load/2filex1/onnxlight", data[-1])
# %%
# Load with ``onnx_light.onnx`` using external data and shared no-copy buffers.
# Each external weights file is read once, then every tensor borrows a view
# into that shared buffer.
data.append(
measure(
"load/2filex1/onnxlight-nocopy",
lambda: onnxl.load(
ext_load_onnx, location=ext_load_data, no_copy=True, touch_raw_data_pages=True
),
)
)
print_stats("load/2filex1/onnxlight-nocopy", data[-1])
# %%
# Load with ``onnx_light.onnx`` using external data and parallel tensor loading.
# Combine external-data loading with ``num_threads > 1`` for maximum throughput.
data.append(
measure(
"load/2filex4/onnxlight",
lambda: onnxl.load(ext_load_onnx, location=ext_load_data, num_threads=4),
)
)
print_stats("load/2filex4/onnxlight", data[-1])
# %%
# Load with ``onnxruntime`` using external data (all optimizations disabled).
# Reload the external-data model with ``onnxruntime``, keeping
# ``ORT_DISABLE_ALL`` so only loading overhead is measured.
data.append(
measure(
"load/2filex1/ort",
lambda: ort.InferenceSession(ext_load_onnx, sess_options=_ort_sess_opts),
)
)
print_stats("load/2filex1/ort", data[-1])
load/2filex1/onnx avg=83.5 ms median=83.6 ms max=84.3 ms std=0.5 ms
load/2filex1/onnxlight avg=52.0 ms median=52.0 ms max=52.3 ms std=0.3 ms
load/2filex1/onnxlight-nocopy avg=4.7 ms median=4.7 ms max=4.7 ms std=0.0 ms
load/2filex4/onnxlight avg=37.6 ms median=37.5 ms max=38.3 ms std=0.4 ms
load/2filex1/ort avg=261.3 ms median=260.9 ms max=262.6 ms std=0.8 ms
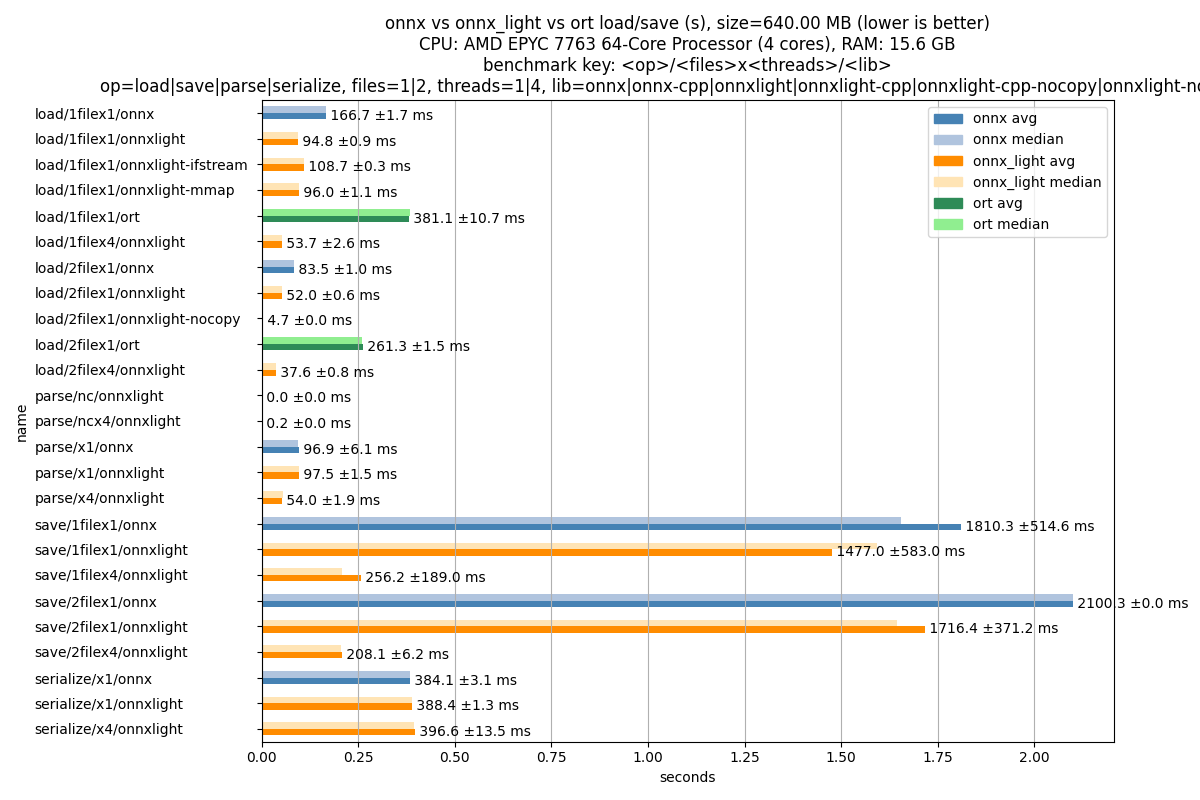
Results#
df = pandas.DataFrame(data).set_index("name").sort_index()
print(df)
df = df.sort_index(ascending=False)
median avg ... max std
name ...
load/1filex1/onnx 0.166848 0.166655 ... 0.167779 0.000875
load/1filex1/onnxlight 0.094797 0.094782 ... 0.095382 0.000440
load/1filex1/onnxlight-ifstream 0.108639 0.108650 ... 0.108851 0.000148
load/1filex1/onnxlight-mmap 0.095863 0.095963 ... 0.096754 0.000585
load/1filex1/ort 0.384123 0.381123 ... 0.387492 0.005454
load/1filex4/onnxlight 0.053849 0.053733 ... 0.055260 0.001320
load/2filex1/onnx 0.083553 0.083499 ... 0.084313 0.000499
load/2filex1/onnxlight 0.051952 0.051971 ... 0.052336 0.000295
load/2filex1/onnxlight-nocopy 0.004669 0.004671 ... 0.004701 0.000019
load/2filex1/ort 0.260949 0.261341 ... 0.262581 0.000751
load/2filex4/onnxlight 0.037528 0.037553 ... 0.038307 0.000433
parse/nc/onnxlight 0.000029 0.000029 ... 0.000031 0.000001
parse/ncx4/onnxlight 0.000206 0.000211 ... 0.000239 0.000015
parse/x1/onnx 0.095135 0.096881 ... 0.102680 0.003102
parse/x1/onnxlight 0.097615 0.097489 ... 0.098325 0.000785
parse/x4/onnxlight 0.054402 0.053965 ... 0.054913 0.000976
save/1filex1/onnx 1.653635 1.810276 ... 2.156589 0.262568
save/1filex1/onnxlight 1.591998 1.476984 ... 1.742602 0.297447
save/1filex4/onnxlight 0.208170 0.256172 ... 0.448991 0.096421
save/2filex1/onnx 2.100343 2.100343 ... 2.100343 0.000000
save/2filex1/onnxlight 1.644106 1.716432 ... 2.091961 0.189380
save/2filex4/onnxlight 0.206572 0.208063 ... 0.214393 0.003181
serialize/x1/onnx 0.383723 0.384051 ... 0.386870 0.001564
serialize/x1/onnxlight 0.388207 0.388419 ... 0.389651 0.000650
serialize/x4/onnxlight 0.393573 0.396580 ... 0.406335 0.006873
[25 rows x 5 columns]
Plot the results.
The average and median are shown for each operation, with the average value
and a 95% confidence interval (derived from the measured standard deviation)
annotated alongside the average bar.
Bars are colored by library: blue family for onnx, orange family for
onnx_light, green family for onnxruntime. Solid shades represent
the average; lighter shades the median.
import matplotlib.patches as mpatches
_onnx_avg = "steelblue"
_onnx_med = "lightsteelblue"
_onnx_light_avg = "darkorange"
_onnx_light_med = "moccasin"
_ort_avg = "seagreen"
_ort_med = "lightgreen"
processor_name = get_processor_name()
total_memory_gb = get_total_memory_gb()
memory_str = f"{total_memory_gb:.1f} GB" if total_memory_gb is not None else "unknown"
cpu_count = os.cpu_count() or 0
ax = df[["avg", "median"]].plot.barh(
title=(
f"onnx vs onnx_light vs ort load/save (s), size={file_size / 2 ** 20:.2f} MB "
f"(lower is better)\n"
f"CPU: {processor_name} ({cpu_count} cores), RAM: {memory_str}\n"
f"benchmark key: <op>/<files>x<threads>/<lib>\n"
f"op=load|save|parse|serialize, files=1|2, threads=1|4, "
f"lib=onnx|onnx-cpp|onnxlight|onnxlight-cpp|onnxlight-cpp-nocopy|"
f"onnxlight-nocopy|ort"
),
xlabel="seconds",
legend=False,
figsize=(12, 8),
)
# Row names use "onnxlight" / "ort" as recorded during benchmarking.
row_names = df.index.tolist()
for container, col in zip(ax.containers, ["avg", "median"]):
for bar, name in zip(container, row_names):
if "onnxlight" in name:
if col == "avg":
bar.set_facecolor(_onnx_light_avg)
elif col == "median":
bar.set_facecolor(_onnx_light_med)
elif "/ort" in name:
if col == "avg":
bar.set_facecolor(_ort_avg)
elif col == "median":
bar.set_facecolor(_ort_med)
else:
if col == "avg":
bar.set_facecolor(_onnx_avg)
elif col == "median":
bar.set_facecolor(_onnx_med)
first_container = ax.containers[0]
for bar, name in zip(first_container, row_names):
avg = df.loc[name, "avg"]
std = df.loc[name, "std"]
if not np.isfinite(avg):
continue
if np.isfinite(std):
ci = 1.96 * std
label = f" {avg * 1e3:.1f} ±{ci * 1e3:.1f} ms"
else:
label = f" {avg * 1e3:.1f} ms"
ax.text(bar.get_width(), bar.get_y() + bar.get_height() / 2.0, label, va="center", ha="left")
legend_handles = [
mpatches.Patch(color=_onnx_avg, label="onnx avg"),
mpatches.Patch(color=_onnx_med, label="onnx median"),
mpatches.Patch(color=_onnx_light_avg, label="onnx_light avg"),
mpatches.Patch(color=_onnx_light_med, label="onnx_light median"),
mpatches.Patch(color=_ort_avg, label="ort avg"),
mpatches.Patch(color=_ort_med, label="ort median"),
]
ax.legend(handles=legend_handles)
ax.grid(axis="x")
for label in ax.get_yticklabels():
label.set_horizontalalignment("left")
ax.tick_params(axis="y", pad=160)
ax.figure.tight_layout()
ax.figure.savefig("plot_onnx_time.png")
Cleanup#
Remove all temporary files created during the benchmark.
shutil.rmtree(tmp_dir, ignore_errors=True)
Total running time of the script: (0 minutes 57.269 seconds)